Редактор метрик
В версии Webim 10.6 увидела свет полная поддержка работы с пользовательскими метриками. Для этих целей в Редакторе Статистики был создан новый подраздел - Редактор метрик. Доступ к нему осуществляется переходом в меню Метрики в разделе Редактор Статистики.
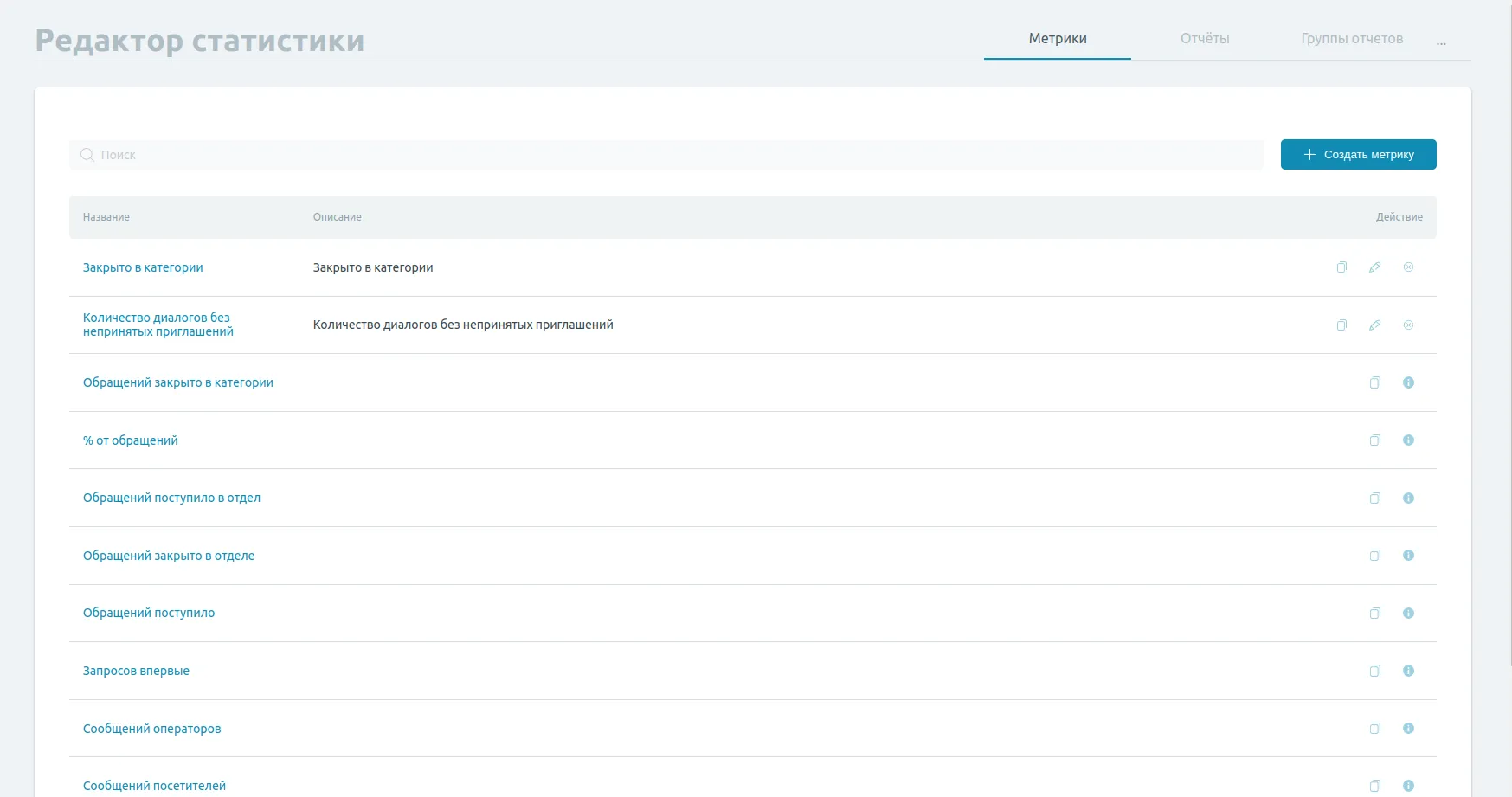
В списке приведены все имеющиеся в системе на данный момент метрики. Эти метрики Вы можете использовать в своих отчётах для отображения именно той информации, которая Вам нужна.
Метрики разделены на два типа:
-
Системные: метрики, присутствующие в системе по умолчанию. Вы не можете их создавать, изменять или удалять, но Вы можете просмотреть и скопировать такую метрику для создания собственной на её основе.
-
Пользовательские: метрики, созданные пользователями системы. При наличии соответствующих прав (см. материал о системе управления доступом) Вы можете создавать, изменять и удалять такие метрики. Пользовательскую метрику можно скопировать для создания новой точно так же, как и системную.
Создание метрик
Для того чтобы создать собственную метрику, нажмите на кнопку Добавить метрику в правом верхнем углу экрана. Перед Вами откроется следующее меню:
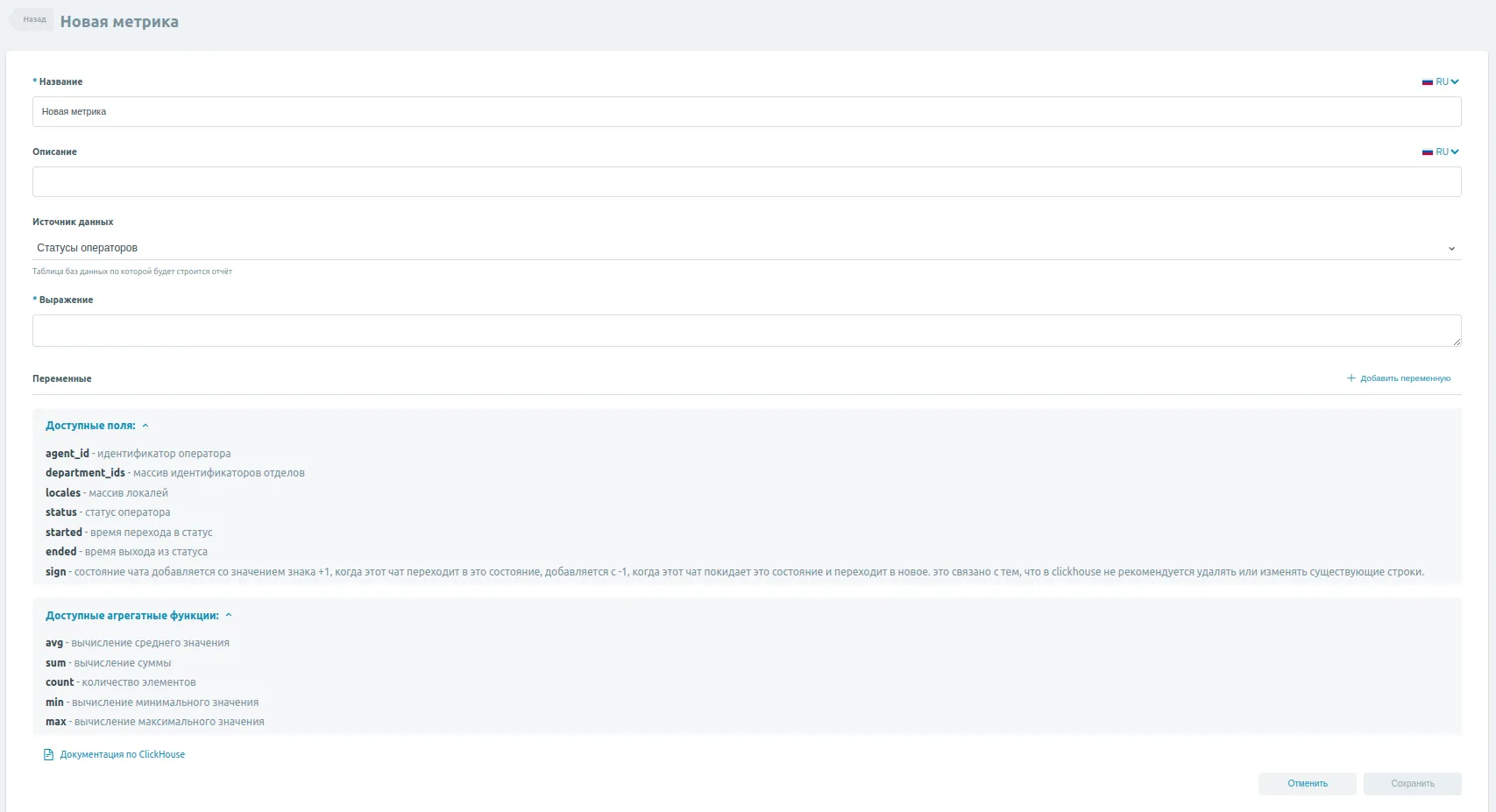
Для того чтобы создать собственную метрику, вам нужно заполнить следующие поля:
-
Название: наименование Вашей метрики. Обязательное для заполнения поле.
-
Описание: описание Вашей метрики - что она подсчитывает, каким образом и т.д. Опциональное поле.
-
Источник данных: выпадающий список, содержащий в себе таблицы базы данных, из которых будет браться информация для подсчёта метрики. В зависимости от выбранного источника данных список доступных полей, приведённый ниже будет изменяться. Обязательное для заполнения поле.
-
Выражение: SQL-выражение, по которому будет выполняться подсчёт метрики. В этом поле допустимо вводить арифметические знаки (
+,-,*,/), имена доступных полей из списка ниже, а также доступные агрегатные функции. Обязательное для заполнения поле.
Раскрывающийся блок Доступные поля отображает доступные для обращения поля, определённые текущим источником данных.
Раскрывающийся блок Доступные агрегатные функции отображает список доступных для вызова агрегатных функций. Этот список неизменяем.
После того как Вы закончите конфигурировать метрику, нажмите на кнопку Сохранить в правом нижнем углу экрана.
Созданную Вами метрику можно использовать в Редакторе отчётов.
Прочие действия с метриками
Копирование
Копирование метрики позволяет вам сразу открыть сконфигурированное окно создания новой метрики для дальнейшей модификации без необходимости изменять изначальную, уже созданную в системе, метрику. Для того чтобы скопировать метрику, нажмите на пиктограмму ![]()
Редактирование
Редактирование метрики аналогично процессу её создания и требует такого же соблюдения всех указанных выше условий. Для перехода к редактированию нужной Вам метрики нажмите на пиктограмму ![]() справа от её названия.
справа от её названия.
Удаление
В том случае, если созданная Вами метрика более не используется, вы можете удалить её, нажав на пиктограмму ![]() напротив этой метрики.
напротив этой метрики.
Внимание!
Метрики удаляются безвозвратно! Если удаляемая вами метрика используется в каких-либо отчётах, она будет удалена из них и её подсчёт в рамках этих отчётов проводиться больше не будет! Подобное поведение системы может быть причиной появления пустых отчётов, потому настоятельно рекомендуем вам проверить, точно ли удаляемая Вами метрика нигде не используется.
Переменные
Также вы можете добавлять в метрики собственные переменные для сокращения выражения при повторяющихся расчётах или для использования в выражении параметров account config. Сделать это можно, нажав на кнопку Добавить переменную в блоке Переменные. Всего доступно два вида переменных: Скалярное значение и Опция account config.

Скалярное значение используется в случае, если вам необходимо записать в переменную одно точное значение для его дальнейшего использования. Для того чтобы использовать его в подсчёте метрики, вам необходимо заполнить следующие поля:
-
Псевдоним: название вашего скалярного значения, объясняющее его суть.
-
Стандартное значение: целочисленное значение переменной.

Опция account config используется в тех случаях, когда вам необходимо получить некоторую информацию из конфигурации системы для использования её в подсчёте метрики. На данный момент по умолчанию доступна лишь одна опция: max_chats_per_operator. Она, как и следует из названия, определяет максимальное количество чатов на оператора. В случае, если Вы хотели бы видеть в своём Редакторе метрик дополнительные опции account config, обратитесь в техническую поддержку.
И скалярные значения, и опции account config имеют свой автоматически генерирующийся или заранее записанный в системе идентификатор, который и используется для обозначения переменной в поле Выражение. Этот идентификатор отображается в соответствующем поле для каждой переменной. Для разных типов переменных он имеет разный вид:
-
Скалярное значение: идентификатор вида
P<num>, гдеnum- порядковый номер скалярного значения относительно времени его создания для текущей метрики. Пример:P0. -
Опция account config: идентификатор вида
config.<parameter>, гдеparameter- название опции account config. Пример:config.max_chats_per_operator.
Вы можете скопировать идентификатор переменной, кликнув по нему левой кнопкой мыши.
Удалить переменную Вы можете, нажав на пиктограмму ![]() у соответствующей переменной.
у соответствующей переменной.
Список функций, принимаемых в выражении метрики
Ниже приведён список функций, принимаемых Редактором метрик. Для получения более подробной справки Вы можете обратиться к официальной документации ClickHouse.
Агрегатные функции
avg(column)
Возвращает среднее значение колонки column. Применимо только к колонкам численных типов.
count(column)
Возвращает количество элементов в колонке column.
max(column)
Возвращает максимальное значение из колонки column.
min(column)
Возвращает минимальное значение из колонки column.
sum(column)
Вычисляет сумму. Работает только для чисел.
uniq(x1, x2, ...)
Приближённо вычисляет количество различных значений аргумента.
Функция принимает переменное число входных параметров. Параметры могут быть числовых типов, а также Tuple, Array, Date, DateTime, String.
Функция:
-
Вычисляет хэш для всех параметров агрегации, а затем использует его в вычислениях.
-
Использует адаптивный алгоритм выборки. В качестве состояния вычисления функция использует выборку хэш-значений элементов размером до
65536.Этот алгоритм очень точен и очень эффективен по использованию CPU. Если запрос содержит небольшое количество этих функций, использование
uniqпочти так же эффективно, как и использование других агрегатных функций. -
Результат детерминирован (не зависит от порядка выполнения запроса).
Эту функцию рекомендуется использовать практически во всех сценариях.
Арифметические функции
abs(a)
Вычисляет абсолютное значение для числа a. То есть, если a меньше либо равно нулю, то возвращает -a. Для беззнаковых типов ничего не делает. Для чисел типа целых со знаком, возвращает число беззнакового типа.
divide(a, b), оператор a / b
Вычисляет частное чисел. Тип результата всегда является типом с плавающей запятой. То есть, деление не целочисленное. Для целочисленного деления, используйте функцию intDiv. При делении на ноль получится inf, -inf или nan.
divideDecimal(a, b[, result_scale])
Совершает деление двух Decimal. Результат будет иметь тип Decimal256. Размер дробной части можно явно задать аргументом result_scale (целочисленная константа из интервала [0, 76]). Если этот аргумент не задан, то scale результата будет равен наибольшему из scale обоих аргументов.
Эта функция работает гораздо медленнее обычной divide. В случае, если нет необходимости иметь фиксированную точность и/или нужны быстрые вычисления, следует использовать divide.
gcd(a, b)
Вычисляет наибольший общий делитель чисел. При делении на ноль или при делении минимального отрицательного числа на минус единицу, выбрасывается исключение.
intDiv(a, b)
Вычисляет частное чисел. Деление целочисленное, с округлением вниз (по абсолютному значению). При делении на ноль или при делении минимального отрицательного числа на минус единицу, выбрасывается исключение.
intDivOrZero(a, b)
Отличается от intDiv тем, что при делении на ноль или при делении минимального отрицательного числа на минус единицу, возвращается ноль.
max2(value1, value2)
Сравнивает два числа и возвращает максимум. Возвращаемое значение приводится к типу Float64.
min2(value1, value2)
Сравнивает два числа и возвращает минимум. Возвращаемое значение приводится к типу Float64.
minus(a, b), оператор a - b
Вычисляет разность чисел. Результат всегда имеет знаковый тип.
Также можно вычитать целые числа из даты и даты-с-временем. Смысл аналогичен plus.
modulo(a, b), оператор a % b
Вычисляет остаток от деления. Тип результата - целое число, если оба аргумента - целые числа. Если один из аргументов является числом с плавающей точкой, результатом будет число с плавающей точкой. Берётся остаток в том же смысле, как это делается в C++. По факту, для отрицательных чисел, используется truncated division. При делении на ноль или при делении минимального отрицательного числа на минус единицу, выбрасывается исключение.
moduloOrZero(a, b)
Аналогично modulo, но возвращает ноль при делении на ноль.
multiply(a, b), оператор a * b
Вычисляет произведение чисел.
multiplyDecimal(a, b[, result_scale])
Совершает умножение двух Decimal. Результат будет иметь тип Decimal256. Размер дробной части результата можно явно задать аргументом result_scale (целочисленная константа из интервала [0, 76]). Если этот аргумент не задан, то размер дробной части результата будет равен наибольшему из размеров обоих аргументов.
negate(a), оператор -a
Вычисляет число, обратное по знаку. Результат всегда имеет знаковый тип.
plus(a, b), оператор a + b
Вычисляет сумму чисел. Также можно складывать целые числа с датой и датой-с-временем. В случае даты, прибавление целого числа означает прибавление соответствующего количества дней. В случае даты-с-временем - прибавление соответствующего количества секунд.
positiveModulo(a, b)
Аналогично modulo, но всегда возвращает положительный остаток.
Функция в 4-5 раз медленнее modulo.
Функции округления
floor(x[, N])
Возвращает наибольшее круглое число, которое меньше или равно, чем x. Круглым называется число, кратное 1 / 10N или ближайшее к нему число соответствующего типа данных, если 1 / 10N не представимо точно. N - целочисленная константа, не обязательный параметр. По умолчанию - ноль, что означает - округлять до целого числа. N может быть отрицательным.
Примеры: floor(123.45, 1) = 123.4, floor(123.45, -1) = 120.
x - любой числовой тип. Результат - число того же типа. Для целочисленных аргументов имеет смысл округление с отрицательным значением N (для неотрицательных N, функция ничего не делает). В случае переполнения при округлении (например, floor(-128, -1)), возвращается implementation specific результат.
round(x[, N])
Округляет значение до указанного десятичного разряда.
Функция возвращает ближайшее значение указанного порядка. В случае, когда заданное число равноудалено от чисел необходимого порядка, для типов с плавающей точкой (Float32/64) функция возвращает то из них, которое имеет ближайшую чётную цифру (банковское округление), для типов с фиксированной точкой (Decimal) функция использует округление в бо́льшую по модулю сторону (математическое округление).
Аргументы:
x — число для округления. Может быть любым выражением, возвращающим числовой тип данных.
N — целое значение.
- Если
N > 0, то функция округляет значение справа от запятой. - Если
N < 0то функция округляет значение слева от запятой. - Если
N = 0, то функция округляет значение до целого. В этом случае аргумент можно опустить.
roundAge(num)
Принимает число. Если число меньше 18 - возвращает 0. Иначе округляет число вниз до чисел из набора: 18, 25, 35, 45, 55. Эта функция специфична для Яндекс.Метрики и предназначена для реализации отчёта по возрасту посетителей.
roundBankers(x[, N])
Округляет число до указанного десятичного разряда.
Если округляемое число равноудалено от соседних чисел, то используется банковское округление. В других случаях функция округляет к ближайшему целому.
Банковское округление позволяет уменьшить влияние округления чисел на результат суммирования или вычитания этих чисел.
Пример суммирования чисел 1.5, 2.5, 3.5 и 4.5 с различным округлением:
- Без округления:
1.5 + 2.5 + 3.5 + 4.5 = 12. - Банковское округление:
2 + 2 + 4 + 4 = 12. - Округление до ближайшего целого:
2 + 3 + 4 + 5 = 14.
roundDown(num, arr)
Принимает число и округляет его до элемента в указанном массиве. Если значение меньше наименьшей границы, возвращается наименьшая граница.
roundDuration(num)
Принимает число. Если число меньше 1 - возвращает 0. Иначе округляет число вниз до чисел из набора: 1, 10, 30, 60, 120, 180, 240, 300, 600, 1200, 1800, 3600, 7200, 18000, 36000. Эта функция специфична для Яндекс.Метрики и предназначена для реализации отчёта по длительности визита.
roundToExp2(num)
Принимает число. Если число меньше 1 - возвращает 0. Иначе округляет число вниз до ближайшей (целой неотрицательной) степени 2.
Функции сравнения
Функции сравнения возвращают всегда 0 или 1 (UInt8).
Сравнивать можно следующие типы:
- числа;
- строки и фиксированные строки;
- даты;
- даты-с-временем;
внутри каждой группы, но не из разных групп.
Например, вы не можете сравнить дату со строкой. Надо использовать функцию преобразования строки в дату или наоборот.
Строки сравниваются побайтово. Более короткая строка меньше всех строк, начинающихся с неё и содержащих ещё хотя бы один символ.
equals, оператор a = b и a == b
Сравнивает a и b между собой. Возвращает 1 в случае равенства и 0 - в случае неравенства.
greater, оператор >
Сравнивает a и b между собой. Возвращает 1 в случае, если a больше b и 0 - в противном случае.
greaterOrEquals, оператор >=
Сравнивает a и b между собой. Возвращает 1 в случае, если a больше либо равно b и 0 - в противном случае.
less, оператор <
Сравнивает a и b между собой. Возвращает 1 в случае, если a меньше b и 0 - в противном случае.
greaterOrEquals, оператор <=
Сравнивает a и b между собой. Возвращает 1 в случае, если a меньше либо равно b и 0 - в противном случае.
notEquals, оператор a != b и a <> b
Сравнивает a и b между собой. Возвращает 1 в случае, если a не равно b и 0 - в противном случае.
Условные функции
greatest(x1, x2, ...)
Возвращает наибольшее значение из списка переданных параметров. Все параметры должны иметь совместимые типы.
if(cond, then, else)
Условное выражение. В отличие от большинства систем, ClickHouse всегда считает оба выражения then и else.
Если условие cond не равно нулю, то возвращается результат выражения then. Если условие cond равно нулю или является NULL, то результат выражения then пропускается и возвращается результат выражения else.
Чтобы вычислять функцию if по короткой схеме, используйте настройку short_circuit_function_evaluation. Если настройка включена, то выражение then вычисляется только для строк, где условие cond верно, а выражение else – для строк, где условие cond неверно.
Аргументы:
cond – проверяемое условие. Может быть UInt8 или NULL.
then – возвращается результат выражения, если условие cond истинно.
else – возвращается результат выражения, если условие cond ложно.
least(x1, x2, ...)
Возвращает наименьшее значение из списка переданных параметров. Все параметры должны иметь совместимые типы.
multiIf(cond_1, then_1, cond_2, then_2, ..., else)
Позволяет более компактно записать оператор CASE в запросе.
Чтобы вычислять функцию multiIf по короткой схеме, используйте настройку short_circuit_function_evaluation. Если настройка включена, то выражение then_i вычисляется только для строк, где условие ((NOT cond_1) AND (NOT cond_2) AND ... AND (NOT cond_{i-1}) AND cond_i) верно, cond_i вычисляется только для строк, где условие((NOT cond_1) AND (NOT cond_2) AND ... AND (NOT cond_{i-1})) верно. Например, при выполнении запроса SELECT multiIf(number = 2, intDiv(1, number), number = 5) FROM numbers(10) не будет сгенерировано исключение из-за деления на ноль.
Аргументы
cond_N — условие, при выполнении которого функция вернёт then_N.
then_N — результат функции при выполнении.
else — результат функции, если ни одно из условий не выполнено.
Функция принимает 2N+1 параметров.
Функция возвращает одно из значений then_N или else, в зависимости от условий cond_N.
Функции преобразования типов
accurateCast(x, T)
Преобразует входное значение x в указанный тип данных T.
Не допускает переполнения при преобразовании числовых типов. Например, accurateCast(-1, 'UInt8') вызовет исключение.
accurateCastOrDefault(x, T[, default_value])
Преобразует входное значение x в указанный тип данных T. Если исходное значение не может быть преобразовано к целевому типу, возвращает значение по умолчанию или default_value, если оно указано.
accurateCastOrNull(x, T)
Преобразует входное значение x в указанный тип данных T.
Если исходное значение не может быть преобразовано к целевому типу, возвращает NULL.
CAST(x, T)
Преобразует входное значение к указанному типу данных. В отличие от функции reinterpret CAST пытается представить то же самое значение в новом типе данных. Если преобразование невозможно, то возникает исключение.
Если входное значение выходит за границы нового типа, то результат переполняется. Например, CAST(-1, 'UInt8') возвращает 255.
dateTime64ToSnowflake(value)
Преобразует дату-время (DateTime64) из value в уникальный ID по алгоритму Snowflake.
dateTimeToSnowflake(value)
Преобразует дату-время (DateTime) из value в уникальный ID по алгоритму Snowflake.
formatRow(format, x, y, ...)
Преобразует произвольные выражения в строку заданного формата.
Аргументы:
format — текстовый формат. Например, CSV, TSV.
x,y, ... — выражения.
Возвращает отформатированную строку (в текстовых форматах обычно с завершающим переводом строки).
Примечание: если формат содержит префикс/суффикс, то он будет записан в каждой строке.
Данная функция поддерживает только строковые форматы вывода.
formatRowNoNewline(format, x, y, ...)
Преобразует произвольные выражения в строку заданного формата. Отличается от функции formatRow тем, что удаляет лишний перевод строки \n в конце, если он есть.
Аргументы:
format — текстовый формат. Например, CSV, TSV.
x,y, ... — выражения.
Возвращает отформатированную строку (в текстовых форматах обычно с завершающим переводом строки).
parseDateTime(str, format[, timezone])
Преобразует строку в DateTime в соответствии со строкой формата MySQL.
Эта функция является операцией, противоположной функции FormatDateTime.
Аргументы
str — строка, подлежащая преобразованию.
format — формат строки.
timezone — Часовой пояс. Необязательный.
Поддерживаемые спецификаторы формата
Все спецификаторы формата, перечисленные в FormatDateTime, за исключением:
%Q: Квартал (1-4)
parseDateTimeOrNull(str, format[, timezone])
Работает аналогично функции parseDateTime, но возвращает NULL, если формат даты не может быть обработан.
parseDateTimeOrZero(str, format[, timezone])
Работает аналогично функции parseDateTime, но возвращает нулевую дату, если формат даты не может быть обработан.
parseDateTimeBestEffort(time_string[, time_zone])
Преобразует дату и время в строковом представлении к типу данных DateTime.
Функция распознаёт форматы ISO 8601,RFC 1123 - 5.2.14 RFC-822 Date and Time Specification, формат даты времени ClickHouse а также некоторые другие форматы.
Аргументы:
time_string — строка, содержащая дату и время для преобразования. String.
time_zone — часовой пояс. Функция анализирует time_string в соответствии с заданным часовым поясом. String.
Поддерживаемые нестандартные форматы:
- Unix timestamp в строковом представлении. 9 или 10 символов.
- Строка с датой и временем:
YYYYMMDDhhmmss,DD/MM/YYYY hh:mm:ss,DD-MM-YY hh:mm,YYYY-MM-DD hh:mm:ss, etc. - Строка с датой, но без времени:
YYYY,YYYYMM,YYYY*MM,DD/MM/YYYY,DD-MM-YYи т.д. - Строка с временем, и с днём:
DD,DD hh,DD hh:mm. В этом случаеMMпринимается равным01. - Строка, содержащая дату и время вместе с информацией о часовом поясе:
YYYY-MM-DD hh:mm:ss ±h:mm, и т.д. Например,2020-12-12 17:36:00 -5:00. - Строка, содержащая дату и время в формате syslog timestamp:
Mmm dd hh:mm:ss. Например,Jun 9 14:20:32.
Для всех форматов с разделителями функция распознаёт названия месяцев, выраженных в виде полного англоязычного имени месяца или в виде первых трёх символов имени месяца. Примеры: 24/DEC/18, 24-Dec-18, 01-September-2018. Если год не указан, вместо него подставляется текущий год. Если в результате получается будущее время (даже на одну секунду впереди текущего момента времени), то текущий год заменяется на прошлый.
parseDateTimeBestEffortOrNull(time_string[, time_zone])
Работает так же как parseDateTimeBestEffort, но возвращает NULL когда получает формат даты который не может быть обработан.
parseDateTimeBestEffortOrZero(time_string[, time_zone])
Работает так же как parseDateTimeBestEffort, но возвращает 0 когда получает формат даты который не может быть обработан.
parseDateTime64BestEffort(time_string [, precision [, time_zone]])
Работает аналогично функции parseDateTimeBestEffort, но также принимает миллисекунды и микросекунды. Возвращает тип данных DateTime.
Аргументы:
time_string — строка, содержащая дату или дату со временем, которые нужно преобразовать. String.
precision — требуемая точность: 3 — для миллисекунд, 6 — для микросекунд. По умолчанию — 3. Необязательный. UInt8.
time_zone — Часовой пояс. Разбирает значение time_string в зависимости от часового пояса. Необязательный. String.
parseDateTime64BestEffortOrNull(time_string [, precision [, time_zone]])
Работает аналогично функции parseDateTime64BestEffort, но возвращает NULL, если формат даты не может быть обработан.
parseDateTime64BestEffortOrZero(time_string [, precision [, time_zone]])
Работает аналогично функции parseDateTime64BestEffort, но возвращает нулевую дату и время, если формат даты не может быть обработан.
parseDateTime64BestEffortUS(time_string [, precision [, time_zone]])
Работает аналогично функции parseDateTime64BestEffort, но разница состоит в том, что в она предполагает американский формат даты (MM/DD/YYYY etc.) в случае неоднозначности.
parseDateTime64BestEffortUSOrNull(time_string [, precision [, time_zone]])
Работает аналогично функции parseDateTime64BestEffort, но разница состоит в том, что в она предполагает американский формат даты (MM/DD/YYYY etc.) в случае неоднозначности и возвращает NULL, если формат даты не может быть обработан.
parseDateTime64BestEffortUSOrZero(time_string [, precision [, time_zone]])
Работает аналогично функции parseDateTime64BestEffort, но разница состоит в том, что в она предполагает американский формат даты (MM/DD/YYYY etc.) в случае неоднозначности и возвращает нулевую дату и время, если формат даты не может быть обработан.
parseDateTimeInJodaSyntax(str, format[, timezone])
Работает аналогично parseDateTime, за исключением того, что строка формата используется в синтаксисе Joda вместо MySQL.
Эта функция является операцией, противоположной функции formatDateTimeInJodaSyntax.
Поддерживаемые спецификаторы формата:
Поддерживаются все спецификаторы формата, перечисленные в formatDateTimeInJoda, за исключением:
S: доли секундыz: часовой поясZ: смещение/идентификатор часового пояса
parseDateTimeInJodaSyntaxOrNull(str, format[, timezone])
Работает аналогично функции parseDateTimeInJodaSyntax, но возвращает NULL, если формат даты не может быть обработан.
parseDateTimeInJodaSyntaxOrZero(str, format[, timezone])
Работает аналогично функции parseDateTimeInJodaSyntax, но возвращает нулевую дату и время, если формат даты не может быть обработан.
reinterpret(x, T)
Использует ту же исходную последовательность байтов в памяти для значения x и повторно интерпретирует ее в соответствии с типом назначения.
Аргументы:
x — Любой тип.
type — Тип назначения. String.
reinterpretAsDate(s)
Функция принимают строку s и интерпретирует байты, расположенные в начале строки, как число в host order (little endian). Если строка имеет недостаточную длину, то функция работают так, как будто строка дополнена необходимым количеством нулевых байт. Если строка длиннее, чем нужно, то лишние байты игнорируются. Дата интерпретируется, как число дней с начала unix-эпохи
reinterpretAsDateTime(s)
Функция принимают строку s и интерпретирует байты, расположенные в начале строки, как число в host order (little endian). Если строка имеет недостаточную длину, то функция работают так, как будто строка дополнена необходимым количеством нулевых байт. Если строка длиннее, чем нужно, то лишние байты игнорируются. дата-с-временем интерпретируется, как число секунд с начала unix-эпохи.
reinterpretAsFixedString(value)
Эта функция принимает число, или дату, или дату со временем и возвращает фиксированную строку, содержащую байты, представляющие соответствующее значение в порядке следования узлов (с меньшим порядком в конце). Нулевые байты удаляются с конца. Например, значение типа UInt32, равное 255, представляет собой фиксированную строку длиной в один байт.
reinterpretAsFloat(s)
Функция принимают строку s и интерпретирует байты, расположенные в начале строки, как Float в host order (little endian). Если строка имеет недостаточную длину, то функция работают так, как будто строка дополнена необходимым количеством нулевых байт. Если строка длиннее, чем нужно, то лишние байты игнорируются.
reinterpretAsInt(s)
Функция принимают строку s и интерпретирует байты, расположенные в начале строки, как Integer в host order (little endian). Если строка имеет недостаточную длину, то функция работают так, как будто строка дополнена необходимым количеством нулевых байт. Если строка длиннее, чем нужно, то лишние байты игнорируются.
reinterpretAsString(value)
Функция принимает число или дату или дату-с-временем и возвращает строку, содержащую байты, представляющие соответствующее значение в host order (little endian). При этом, отбрасываются нулевые байты с конца. Например, значение 255 типа UInt32 будет строкой длины 1 байт.
reinterpretAsUInt(s)
Функция принимают строку s и интерпретирует байты, расположенные в начале строки, как UInt в host order (little endian). Если строка имеет недостаточную длину, то функция работают так, как будто строка дополнена необходимым количеством нулевых байт. Если строка длиннее, чем нужно, то лишние байты игнорируются.
reinterpretAsUUID(fixed_string)
Функция принимает строку из 16 байт и интерпретирует ее байты в порядок от старшего к младшему. Если строка имеет недостаточную длину, то функция работает так, как будто строка дополнена необходимым количеством нулевых байтов с конца. Если строка длиннее, чем 16 байтов, то лишние байты с конца игнорируются.
second()
То же, что и toSecond.
snowflakeToDateTime(value [, time_zone])
Извлекает время из Snowflake ID в формате DateTime.
Аргументы:
value — Snowflake ID. Int64.
time_zone — временная зона сервера. Функция распознает time_string в соответствии с часовым поясом. Необязательный. String.
snowflakeToDateTime64(value [, time_zone])
Извлекает время из Snowflake ID в формате DateTime64.
toDate(value)
Конвертирует аргумент в значение Date.
Аргументы:
value — Значение для преобразования. String, Int, Date или DateTime.
Если value является числом выглядит как UNIX timestamp (больше чем 65535), оно интерпретируется как DateTime, затем обрезается до Date учитывавая текущий часовой пояс. Если value является числом и меньше чем 65536, оно интерпретируется как количество дней с 1970-01-01.
toDateOrDefault(value, [default_value])
Как toDate, но в случае неудачи возвращает значение по умолчанию (или второй аргумент (если указан), или нижняя граница Date).
toDateOrNull(value)
Как toDate, но в случае неудачи возвращает NULL. Поддерживается только аргумент типа String.
toDateOrZero(value)
Как toDate, но в случае неудачи возвращает нижнюю границу Date. Поддерживается только аргумент типа String.
toDate32(value)
Конвертирует аргумент в значение типа Date32. Если значение выходит за границы диапазона, возвращается пограничное значение Date32. Если аргумент имеет тип Date, учитываются границы типа Date.
toDate32OrDefault(value, [default_value])
Конвертирует аргумент в значение типа Date32. Если значение выходит за границы диапазона, возвращается нижнее пограничное значение Date32. Если аргумент имеет тип Date, учитываются границы типа Date. Возвращает значение по умолчанию, если получен недопустимый аргумент.
toDate32OrNull(value)
То же самое, что и toDate32, но возвращает NULL, если получен недопустимый аргумент.
toDate32OrZero(value)
То же самое, что и toDate32, но возвращает минимальное значение типа Date32, если получен недопустимый аргумент.
toDateTime(value, [time_zone])
Конвертирует аргумент в значение DateTime.
Аргументы:
value — Значение для преобразования. String, Int, Date или DateTime.
time_zone — Часовой пояс. String.
Если value является числом, то оно интерпретируется как число секунд с начала Unix-эпохи (Unix Timestamp).
Если же value - строка (String), то оно может быть интерпретировано и как Unix Timestamp, и как строковое представление даты / даты со временем.
Ввиду неоднозначности запрещён парсинг строк длиной 4 и меньше. Так, строка '1999' могла бы представлять собой как год (неполное строковое представление даты или даты со временем), так и Unix Timestamp. Строки длиной 5 символов и более не несут неоднозначности, а следовательно, их парсинг разрешён.
toDateTimeOrDefault(value, [time_zone], [default_value])
Как toDateTime, но в случае неудачи возвращает значение по умолчанию (или третий аргумент (если указан), или нижняя граница DateTime).
toDateTimeOrNull(value, [time_zone])
Как toDateTime, но в случае неудачи возвращает NULL. Поддерживается только аргумент типа String.
toDateTimeOrZero(value, [time_zone])
Как toDateTime, но в случае неудачи возвращает нижнюю границу DateTime. Поддерживается только аргумент типа String.
toDateTime64(value, [time_zone])
То же самое, что и toDateTime, но возвращаемое значение имеет тип DateTime64.
toDateTime64OrDefault(value, [time_zone], [default_value])
То же самое, что и toDateTime64, но возвращает значение DateTime64 по умолчанию или default_value (если задано), если получен недопустимый аргумент.
toDateTime64OrNull(value, [time_zone])
То же самое, что и toDateTime64, но возвращает NULL, если получен недопустимый аргумент.
toDateTime64OrZero(value, [time_zone])
То же самое, что и toDateTime64, но возвращает минимальное значение типа DateTime64, если получен недопустимый аргумент.
toDecimal(value, S)
Преобразует value к типу данных Decimal с точностью S. value может быть числом или строкой. Параметр S (scale) задаёт число десятичных знаков.
Аргументы:
value — выражение, возвращающее значение типа String. ClickHouse ожидает текстовое представление десятичного числа. Например, '1.111'.
S — количество десятичных знаков в результирующем значении.
Возвращаемое значение:
Значение типа Nullable(Decimal(P,S)). Значение содержит:
- Число с
Sдесятичными знаками, если ClickHouse распознал число во входной строке. NULL, если ClickHouse не смог распознать число во входной строке или входное число содержит больше чемSдесятичных знаков.
toDecimalString(number, scale)
Принимает любой численный тип первым аргументом, возвращает строковое десятичное представление числа с точностью, заданной вторым аргументом.
Возвращает строку (String), представляющая собой десятичное представление входного числа с заданной длиной дробной части. При необходимости число округляется по стандартным правилам арифметики.
Аргументы:
number — Значение любого числового типа: Int, UInt, Float, Decimal.
scale — Требуемое количество десятичных знаков после запятой, UInt8.
- Значение
scaleдля типовDecimalиInt,UIntдолжно не превышать77(так как это наибольшее количество значимых символов для этих типов). - Значение
scaleдля типаFloatне должно превышать60.
toFixedString(s, N)
Преобразует аргумент типа String в тип FixedString(N) (строку фиксированной длины N). N должно быть константой. Если строка имеет меньше байт, чем N, то она дополняется нулевыми байтами справа. Если строка имеет больше байт, чем N - выбрасывается исключение.
toFloat(value)
Преобраует входное значение к типу Float.
Аргументы:
value — выражение, возвращающее число или строку с десятичным представление числа. Бинарное, восьмеричное и шестнадцатеричное представление числа не поддержаны. Ведущие нули обрезаются.
Функции используют округление к нулю, т.е. обрезают дробную часть числа.
Поведение функции для аргументов NaN и Inf не определено. Если передать строку, содержащую отрицательное число, например '-32', ClickHouse генерирует исключение. При использовании функции помните о возможных проблемах при преобразовании чисел.
toInt(value)
Преобразует входное значение к типу Int.
Аргументы:
value — выражение, возвращающее число или строку с десятичным представление числа. Бинарное, восьмеричное и шестнадцатеричное представление числа не поддержаны. Ведущие нули обрезаются.
Функции используют округление к нулю, т.е. обрезают дробную часть числа.
Поведение функции для аргументов NaN и Inf не определено. При использовании функции помните о возможных проблемах при преобразовании чисел.
toInterval(number)
Приводит аргумент из числового типа данных к типу данных IntervalType.
Аргументы:
number — длительность интервала. Положительное целое число.
toLowCardinality(value)
Преобразует входные данные в версию LowCardinality того же типа данных.
Чтобы преобразовать данные из типа LowCardinality, используйте функцию CAST. Например,CAST(x as String).
toString(value)
Функции преобразования между числами, строками (но не фиксированными строками), датами и датами-с-временем. Все эти функции принимают один аргумент.
При преобразовании в строку или из строки, производится форматирование или парсинг значения по тем же правилам, что и для формата TabSeparated (и почти всех остальных текстовых форматов). Если распарсить строку не удаётся - выбрасывается исключение и выполнение запроса прерывается.
При преобразовании даты в число или наоборот, дате соответствует число дней от начала unix эпохи. При преобразовании даты-с-временем в число или наоборот, дате-с-временем соответствует число секунд от начала unix эпохи.
Форматы даты и даты-с-временем для функций toDate/toDateTime определены следующим образом:
YYYY-MM-DD
YYYY-MM-DD hh:mm:ss
В качестве исключения, если делается преобразование из числа типа UInt32, Int32, UInt64, Int64 в Date, и если число больше или равно 65536, то число рассматривается как unix timestamp (а не как число дней) и округляется до даты. Это позволяет поддержать распространённый случай, когда пишут toDate(unix_timestamp), что иначе было бы ошибкой и требовало бы написания более громоздкого toDate(toDateTime(unix_timestamp)).
Преобразование между датой и датой-с-временем производится естественным образом: добавлением нулевого времени или отбрасыванием времени.
Преобразование между числовыми типами производится по тем же правилам, что и присваивание между разными числовыми типами в C++.
Дополнительно, функция toString от аргумента типа DateTime может принимать второй аргумент String - имя тайм-зоны. Пример: Asia/Yekaterinburg В этом случае, форматирование времени производится согласно указанной тайм-зоне.
toStringCutToZero(s)
Принимает аргумент типа String или FixedString. Возвращает String, вырезая содержимое строки до первого найденного нулевого байта.
toUInt(value)
Преобраует входное значение к типу UInt.
Аргументы:
value — выражение возвращающее число или строку с десятичным представление числа. Бинарное, восьмеричное и шестнадцатеричное представление числа не поддержаны. Ведущие нули обрезаются.
Функция использует округление к нулю, т.е. обрезает дробную часть числа.
Поведение функции для аргументов NaN и Inf не определено. Если передать строку, содержащую отрицательное число, например '-32', ClickHouse генерирует исключение. При использовании функции помните о возможных проблемах при преобразовании чисел.
toUnixTimestamp64Micro(value)
Преобразует значение DateTime64 в значение Int64 с фиксированной точностью менее одной секунды. Входное значение округляется соответствующим образом вверх или вниз в зависимости от его точности.
Возвращаемое значение — это временная метка в UTC, а не в часовом поясе DateTime64.
toUnixTimestamp64Milli(value)
Преобразует значение DateTime64 в значение Int64 с фиксированной точностью менее одной секунды. Входное значение округляется соответствующим образом вверх или вниз в зависимости от его точности.
Возвращаемое значение — это временная метка в UTC, а не в часовом поясе DateTime64.
toUnixTimestamp64Nano(value)
Преобразует значение DateTime64 в значение Int64 с фиксированной точностью менее одной секунды. Входное значение округляется соответствующим образом вверх или вниз в зависимости от его точности.
Возвращаемое значение — это временная метка в UTC, а не в часовом поясе DateTime64.
Функции для работы с Nullable-аргументами
assumeNotNull(x)
Приводит значение типа Nullable к не Nullable, если значение не NULL.
coalesce(x, ...)
Последовательно слева-направо проверяет являются ли переданные аргументы NULL и возвращает первый не NULL.
В качестве аргументов принимается произвольное количество параметров не составного типа. Все параметры должны быть совместимы по типу данных.
Если все аргументы NULL, функция возвращает NULL.
ifNull(x,alt)
Возвращает альтернативное alt значение, если основной аргумент x — NULL.
Аргументы:
x — значение для проверки на NULL.
alt — значение, которое функция вернёт, если x — NULL.
isNotNull(x)
Проверяет не является ли аргумент NULL. Возвращает 1, если аргумент не является NULL, возвращает 0 в противном случае.
Аргументы:
x — значение с не составным типом данных.
isNull(x)
Проверяет является ли аргумент NULL. Возвращает 1, если аргумент является NULL, возвращает 0 в противном случае.
Аргументы:
x — значение с не составным типом данных.
isZeroOrNull(x)
Проверяет, равен ли аргумент 0 или NULL. Возвращает 1, если аргумент является 0 или NULL, возвращает 0 в противном случае.
Аргументы:
x — значение с не составным типом данных.
nullIf(x, y)
Возвращает NULL, если аргументы равны и x в противном случае.
Аргументы:
x, y — значения для сравнивания. Они должны быть совместимых типов, иначе ClickHouse сгенерирует исключение.
toNullable(x)
Преобразует тип аргумента к Nullable.
Аргументы:
x — значение произвольного не составного типа.
Функции для работы с датами и временем
addDays(x, days)
Прибавляет к дате или дате-времени x указанное в days количество дней.
Аргументы:
x - дата или дата-время. Тип String. Принимаемым форматом является любой из общепринятых форматов дат и даты-времени.
days - количество единиц времени. Тип Int.
addHours(x, hours)
Прибавляет к дате-времени x указанное в hours количество часов.
Аргументы:
x - дата или дата-время. Тип String. Принимаемым форматом является любой из общепринятых форматов дат и даты-времени.
hours - количество единиц времени. Тип Int.
addMinutes(x, minutes)
Прибавляет к дате-времени x указанное в minutes количество минут.
Аргументы:
x - дата или дата-время. Тип String. Принимаемым форматом является любой из общепринятых форматов дат и даты-времени.
minutes - количество единиц времени. Тип Int.
addMonths(x, months)
Прибавляет к дате или дате-времени x указанное в months количество месяцев.
Аргументы:
x - дата или дата-время. Тип String. Принимаемым форматом является любой из общепринятых форматов дат и даты-времени.
months - количество единиц времени. Тип Int.
addQuartets(x, quarters)
Прибавляет к дате или дате-времени x указанное в quarters количество кварталов (периодов по три месяца).
Аргументы:
x - дата или дата-время. Тип String. Принимаемым форматом является любой из общепринятых форматов дат и даты-времени.
quarters - количество единиц времени. Тип Int.
addSeconds(x, seconds)
Прибавляет к дате-времени x указанное в seconds количество секунд.
Аргументы:
x - дата или дата-время. Тип String. Принимаемым форматом является любой из общепринятых форматов дат и даты-времени.
seconds - количество единиц времени. Тип Int.
addWeeks(x, weeks)
Прибавляет к дате или дате-времени x указанное в weeks количество недель.
Аргументы:
x - дата или дата-время. Тип String. Принимаемым форматом является любой из общепринятых форматов дат и даты-времени.
weeks - количество единиц времени. Тип Int.
addYears(x, years)
Прибавляет к дате или дате-времени x указанное в years количество лет.
Аргументы:
x - дата или дата-время. Тип String. Принимаемым форматом является любой из общепринятых форматов дат и даты-времени.
years - количество единиц времени. Тип Int.
age(unit, startdate, enddate, [timezone])
Вычисляет компонент unit разницы между startdate и enddate. Разница вычисляется с точностью в 1 микросекунду. Например, разница между 2021-12-29 и 2022-01-01 3 дня для единицы day, 0 месяцев для единицы month, 0 лет для единицы year.
Аргументы:
unit — единица измерения времени, в которой будет выражено возвращаемое значение функции. Тип String. Возможные значения:
microsecond(возможные сокращения:us,u)millisecond(возможные сокращения:ms)second(возможные сокращения:ss,s)minute(возможные сокращения:mi,n)hour(возможные сокращения:hh,h)day(возможные сокращения:dd,d)week(возможные сокращения:wk,ww)month(возможные сокращения:mm,m)quarter(возможные сокращения:qq,q)year(возможные сокращения:yyyy,yy)
startdate — первая дата или дата со временем, которая вычитается из enddate. Тип String. Принимаемым форматом является любой из общепринятых форматов дат и даты-времени.
enddate — вторая дата или дата со временем, из которой вычитается startdate. Тип String. Принимаемым форматом является любой из общепринятых форматов дат и даты-времени.
timezone — часовой пояс (необязательно). Если этот аргумент указан, то он применяется как для startdate, так и для enddate. Если этот аргумент не указан, то используются часовые пояса аргументов startdate и enddate. Если часовые пояса аргументов startdate и enddate не совпадают, то результат не определен. Тип String.
date_add(unit, value, date)
Добавляет интервал времени или даты к указанной дате или дате со временем.
Аргументы:
unit — единица измерения времени, в которой задан интервал для добавления. String. Возможные значения:
secondminutehourdayweekmonthquarteryear
value — значение интервала для добавления. Int.
date — дата или дата со временем, к которой добавляется value. String. Принимается любой из общепринятых форматов дат и даты-времени.
date_diff('unit', startdate, enddate, [timezone])
Также datediff.
Вычисляет разницу указанных границ unit, пересекаемых между startdate и enddate.
Аргументы:
unit — единица измерения времени, в которой будет выражено возвращаемое значение функции. Тип String. Возможные значения:
microsecond(возможные сокращения:us,u)millisecond(возможные сокращения:ms)second(возможные сокращения:ss,s)minute(возможные сокращения:mi,n)hour(возможные сокращения:hh,h)day(возможные сокращения:dd,d)week(возможные сокращения:wk,ww)month(возможные сокращения:mm,m)quarter(возможные сокращения:qq,q)year(возможные сокращения:yyyy,yy)
startdate — первая дата или дата со временем, которая вычитается из enddate. Тип String. Принимаемым форматом является любой из общепринятых форматов дат и даты-времени.
enddate — вторая дата или дата со временем, из которой вычитается startdate. Тип String. Принимаемым форматом является любой из общепринятых форматов дат и даты-времени.
timezone — часовой пояс (необязательно). Если этот аргумент указан, то он применяется как для startdate, так и для enddate. Если этот аргумент не указан, то используются часовые пояса аргументов startdate и enddate. Если часовые пояса аргументов startdate и enddate не совпадают, то результат не определен. Тип String.
date_sub(unit, value, date)
Вычитает интервал времени или даты из указанной даты или даты со временем.
Аргументы:
unit — единица измерения времени, в которой задан интервал для добавления. String. Возможные значения:
secondminutehourdayweekmonthquarteryear
value — значение интервала для добавления. Int.
date — дата или дата со временем, к которой добавляется value. String. Принимается любой из общепринятых форматов дат и даты-времени.
date_trunc(unit, value[, timezone])
Отсекает от даты и времени части, меньшие чем указанная часть.
Аргументы:
unit — единица измерения времени, в которой задан интервал для добавления. String. Возможные значения:
secondminutehourdayweekmonthquarteryear
value — дата или дата со временем, к которой добавляется value. String. Принимается любой из общепринятых форматов дат и даты-времени.
timezone — часовой пояс для возвращаемого значения (необязательно). Если параметр не задан, используется часовой пояс параметра value. String.
dateName(date_part, date)
Возвращает указанную часть даты.
Аргументы:
date_part — часть даты. Возможные значения: 'year', 'quarter', 'month', 'week', 'dayofyear', 'day', 'weekday', 'hour', 'minute', 'second'. String.
date — дата в любом общепринятом формате. String.
timezone — часовой пояс. Необязательный аргумент. String.
formatDateTime(Time, Format[, Timezone])
Функция преобразует дату-и-время в строку по заданному шаблону. Важно: шаблон — константное выражение, поэтому использовать разные шаблоны в одной колонке не получится.
Используйте поля подстановки для того, чтобы определить шаблон для выводимой строки. В колонке «Пример» результат работы функции для времени 2018-01-02 22:33:44.
| Поле | Описание | Пример |
|---|---|---|
%C |
номер года, поделённый на 100 (00-99) | 20 |
%d |
день месяца, с ведущим нулём (01-31) | 02 |
%D |
короткая запись %m/%d/%y |
01/02/18 |
%e |
день месяца, с ведущим пробелом ( 1-31) | 2 |
%F |
короткая запись %Y-%m-%d |
2018-01-02 |
%G |
четырехзначный формат вывода ISO-года, который основывается на особом подсчете номера недели согласно стандарту ISO 8601, обычно используется вместе с %V |
2018 |
%g |
двузначный формат вывода года по стандарту ISO 8601 | 18 |
%H |
час в 24-часовом формате (00-23) | 22 |
%I |
час в 12-часовом формате (01-12) | 10 |
%j |
номер дня в году, с ведущими нулями (001-366) | 002 |
%m |
месяц, с ведущим нулём (01-12) | 01 |
%M |
минуты, с ведущим нулём (00-59) | 33 |
%n |
символ переноса строки (‘’) |
|
%p |
обозначения AM или PM |
PM |
%Q |
квартал (1-4) | 1 |
%R |
короткая запись %H:%M |
22:33 |
%S |
секунды, с ведущими нулями (00-59) | 44 |
%t |
символ табуляции (’) |
|
%T |
формат времени ISO 8601, одинаковый с %H:%M:%S |
22:33:44 |
%u |
номер дня недели согласно ISO 8601, понедельник - 1, воскресенье - 7 | 2 |
%V |
номер недели согласно ISO 8601 (01-53) | 01 |
%w |
номер дня недели, начиная с воскресенья (0-6) | 2 |
%y |
год, последние 2 цифры (00-99) | 18 |
%Y |
год, 4 цифры | 2018 |
%z |
Смещение времени от UTC +HHMM или -HHMM |
-0500 |
%% |
символ % |
% |
formatDateTimeInJodaSyntax(Time, Format[, Timezone])
Функция аналогична formatDateTime с той разницей, что форматы даты и времени в этой функции должны быть представлены в стиле Joda, а не MySQL.
Принимаемые значения Format:
| Плейсхолдер | Значение | Представление | Пример |
|---|---|---|---|
G |
Эра | Текст | AD |
C |
Век | Число | 20 |
Y |
Год | Год | 1996 |
e |
День недели | Число | 2 |
E |
День недели | Текст | Tuesday; Tue |
y |
Год | Год | 1996 |
D |
День года | Число | 189 |
M |
Месяц | Месяц | July; Jul; 07 |
d |
День | Число | 10 |
a |
Полдень | Текст | PM |
K |
Час полдня | Число | 0 |
h |
Номер часа полдня | Число | 12 |
H |
Час | Число | 0 |
k |
Номер часа | Число | 24 |
m |
Минута | Число | 30 |
s |
Секунда | Число | 55 |
z |
Часовой пояс (короткое имя не поддерживается) | Текст | Pacific Standard Time; PST |
'' |
Одиночная кавычка | Символ | ' |
fromModifiedJulianDay(day)
Преобразует измененный номер дня по юлианскому календарю из day в пролепетическую дату по григорианскому календарю в текстовой форме YYYY-MM-DD. Эта функция поддерживает номера дней от -678941 до 2973119 (которые представляют 0000-01-01 и 9999-12-31 соответственно). Это вызывает исключение, если номер дня находится за пределами поддерживаемого диапазона.
fromModifiedJulianDayOrNull(day)
Действует по тому же принципу, что и fromModifiedJulianDay, но вместо исключения при выходе за пределы поддерживаемого диапазона возвращает NULL.
fromUnixTimestamp(timestamp, [format, [timezone]])
Эта функция преобразует временную метку UNIX в календарную дату и время суток.
Ее можно вызвать двумя способами:
-
При задании единственного аргумента типа
Integerона возвращает значение типаDateTime, т.е. ведет себя какToDateTime. -
При задании двух или трех аргументов, где первым аргументом является значение типа
Integer,Date,Date32,DateTimeилиDateTime64, вторым аргументом является строка постоянного формата, а третьим аргументом является необязательная строка постоянного часового пояса, функция возвращает значение типаString, т.е. она ведет себя какFormatDateTime. В этом случае используется стиль формата даты и времени MySQL.
fromUnixTimestampInJodaSyntax(timestamp, [format, [timezone]])
Действует по тому же принципу, что и fromUnixTimestamp, но при передаче двух или трёх аргументов форматирование задаётся в стиле Joda, а не MySQL.
fromUnixTimestamp64Micro(value [, ti])
Преобразует значение Int64 из value в значение DateTime64 с фиксированной точностью менее одной секунды и дополнительным часовым поясом из ti. Входное значение округляется соответствующим образом вверх или вниз в зависимости от его точности. Обратите внимание, что входное значение обрабатывается как метка времени UTC, а не метка времени в заданном (или неявном) часовом поясе.
fromUnixTimestamp64Milli(value [, ti])
Преобразует значение Int64 из value в значение DateTime64 с фиксированной точностью менее одной секунды и дополнительным часовым поясом из ti. Входное значение округляется соответствующим образом вверх или вниз в зависимости от его точности. Обратите внимание, что входное значение обрабатывается как метка времени UTC, а не метка времени в заданном (или неявном) часовом поясе.
fromUnixTimestamp64Nano(value [, ti])
Преобразует значение Int64 из value в значение DateTime64 с фиксированной точностью менее одной секунды и дополнительным часовым поясом из ti. Входное значение округляется соответствующим образом вверх или вниз в зависимости от его точности. Обратите внимание, что входное значение обрабатывается как метка времени UTC, а не метка времени в заданном (или неявном) часовом поясе.
fromUTCTimestamp(value, timezone)
Преобразует значение value типа DateTime/DateTime64 из часового пояса UTC в временную метку другого часового пояса, переданного в timezone
makeDate(year, month, day), makeDate(year, day_of_year)
Преобразует аргументы в возвращаемое значение типа Date. Возможны два варианта вызова:
- В качестве аргументов используются год, месяц и день
- В качестве аргументов используются год и номер дня в году
makeDate32(year, month, day), makeDate32(year, day_of_year)
Аналогично makeDate, но возвращаемое значение имеет тип Date32
makeDateTime(year, month, day, hour, minute, second[, timezone])
Преобразует аргументы в возвращаемое значение типа DateTime.
Аргументы:
year— год.Integer,FloatилиDecimal.month— месяц.Integer,FloatилиDecimal.day— день.Integer,FloatилиDecimal.hour— час.Integer,FloatилиDecimal.minute— минута.Integer,FloatилиDecimal.second— секунда.Integer,FloatилиDecimal.timezone— часовой пояс (опционально).
makeDateTime64(year, month, day, hour, minute, second[, timezone])
АналогичноmakeDateTime, но возвращаемое значение имеет тип DateTime64.
monthName(date)
Возвращает имя месяца.
Аргументы:
date — дата или дата со временем. Date, DateTime или DateTime64.
now([timezone])
Возвращает текущую дату и время.
Аргументы:
timezone — часовой пояс для возвращаемого значения (необязательно). String.
now64([scale], [timezone])
Возвращает текущую дату и время с точностью до секунды на момент анализа запроса. Функция является постоянным выражением.
Аргументы:
scale - размер тика (точность): 10^-точность секунд. Допустимый диапазон: [0:9]. Обычно используются значения - 3 (по умолчанию) (миллисекунды), 6 (микросекунды), 9 (наносекунды).
timezone — часовой пояс для возвращаемого значения (необязательно). String.
nowInBlock()
Возращает текующию дату и время в момент обработки блока данных. В отличие от функции now, возращаемое значение не константа, и будет возрващаться разлчиные значения в разных блоках данных при долгих запросах.
serverTimeZone()
Возвращает часовой пояс сервера по умолчанию, в т.ч. установленный timezone Если функция вызывается в контексте распределенной таблицы, то она генерирует обычный столбец со значениями, актуальными для каждого шарда. Иначе возвращается константа.
subtractYears, subtractQuarters, subtractMonths, subtractWeeks, subtractDays, subtractHours, subtractMinutes, subtractSeconds
Эти функции вычитают единицы интервала, указанного в названии функции, из даты, даты со временем или даты, закодированной в строке / даты со временем. Возвращается дата или дата со временем.
timeSlot(value)
Округляет время до получаса. Эта функция является специфичной для Яндекс.Метрики, так как полчаса - минимальное время, для которого, если соседние по времени хиты одного посетителя на одном счётчике отстоят друг от друга строго более, чем на это время, визит может быть разбит на два визита. То есть, кортежи (номер счётчика, идентификатор посетителя, тайм-слот) могут использоваться для поиска хитов, входящий в соответствующий визит.
timeSlots(StartTime, Duration,[, Size])
Для интервала, начинающегося в StartTime и длящегося Duration секунд, возвращает массив моментов времени, кратных Size. Параметр Size указывать необязательно, по умолчанию он равен 1800 секундам (30 минутам) - необязательный параметр.
Возвращает массив DateTime/DateTime64 (тип будет совпадать с типом параметра StartTime). Для DateTime64 масштаб (scale) возвращаемой величины может отличаться от масштаба фргумента StartTime - результат будет иметь наибольший масштаб среди всех данных аргументов.
timestamp_add(date, INTERVAL value unit)
Добавляет интервал времени к указанной дате или дате со временем. Возвращает дату или дату со временем, полученную в результате добавления value, выраженного в unit, к date.
Аргументы:
date — дата или дата со временем. Date или DateTime.
value — значение интервала для добавления. Int.
unit — единица измерения времени, в которой задан интервал для добавления. String. Возможные значения:
secondminutehourdayweekmonthquarteryear
timestamp_sub(unit, value, date)
Вычитает интервал времени из указанной даты или даты со временем. Возвращает дату или дату со временем, полученную в результате вычитания value, выраженного в unit, к date.
Аргументы:
unit — единица измерения времени, в которой задан интервал для добавления. String. Возможные значения:
secondminutehourdayweekmonthquarteryear
value — значение интервала для добавления. Int.
date — дата или дата со временем. Date или DateTime.
timeZone()
Возвращает часовой пояс сервера, считающийся умолчанием для текущей сессии: значение параметра session_timezone, если установлено.
Если функция вызывается в контексте распределенной таблицы, то она генерирует обычный столбец со значениями, актуальными для каждого шарда. Иначе возвращается константа.
timeZoneOf(date)
Возвращает название часового пояса для значений типа DateTime и DateTime64.
timeZoneOffset(date)
Возвращает смещение часового пояса в секундах от UTC. Функция учитывает летнее время и исторические изменения часовых поясов, которые действовали на указанную дату. Для вычисления смещения используется информация из базы данных IANA.
today()
Возвращает текущую дату на момент выполнения запроса. Функция не требует аргументов. То же самое, что toDate(now()).
toDayOfMonth(date)
Переводит дату или дату-с-временем в число типа UInt8, содержащее номер дня в месяце (1-31).
toDayOfWeek(date)
Переводит дату или дату-с-временем в число типа UInt8, содержащее номер дня в неделе (понедельник - 1, воскресенье - 7).
toDayOfYear(date)
Переводит дату или дату-с-временем в число типа UInt16, содержащее номер дня года (1-366).
toDaysSinceYearZero(date[, time_zone])
Возвращает для заданной даты количество дней, прошедших с 1 января 0000 года в пролептическом григорианском календаре, определенном ISO 8601. Расчет такой же, как в функции TO_DAYS() в MySQL.
toHour(date, [time_zone])
Переводит дату-с-временем в число типа UInt8, содержащее номер часа в сутках (0-23). Функция исходит из допущения, что перевод стрелок вперёд, если осуществляется, то на час, в два часа ночи, а перевод стрелок назад, если осуществляется, то на час, в три часа ночи (что, в общем, не верно - даже в Москве два раза перевод стрелок был осуществлён в другое время).
toISOWeek(date)
Переводит дату или дату-с-временем в число типа UInt8, содержащее номер ISO недели. Начало ISO года отличается от начала обычного года, потому что в соответствии с ISO 8601:1988 первая неделя года - это неделя с четырьмя или более днями в этом году.
1 Января 2017 г. - воскресение, т.е. первая ISO неделя 2017 года началась в понедельник 2 января, поэтому 1 января 2017 это последняя неделя 2016 года.
toISOYear(date)
Переводит дату или дату-с-временем в число типа UInt16, содержащее номер ISO года. ISO год отличается от обычного года, потому что в соответствии с ISO 8601:1988 ISO год начинается необязательно первого января.
toLastDayOfMonth(date, [timezone])
Округляет дату или дату-с-временем до последнего числа месяца. Возвращается дата.
Возвращаемое значение для некорректных дат зависит от реализации. ClickHouse может вернуть нулевую дату, выбросить исключение, или выполнить «естественное» перетекание дат между месяцами.
toLastDayOfWeek(t, [mode], [timezone])
Округляет дату или дату-с-временем вперёд, до ближайшей субботы или воскресенья, в соответствии с mode. Возвращается дата. Аргумент mode работает точно так же, как аргумент mode toWeek(). Если аргумент mode опущен, то используется режим 0.
toMinute(date)
Переводит дату-с-временем в число типа UInt8, содержащее номер минуты в часе (0-59).
toModifiedJulianDay(date)
Преобразует пролепетическую дату по григорианскому календарю в текстовой форме ГГГГ-ММ-ДД в измененный номер юлианского дня в Int32. Эта функция поддерживает даты от 0000-01-01 до 9999-12-31. Это вызывает исключение, если аргумент не может быть проанализирован как дата или дата недействительна.
toModifiedJulianDayOrNull(date)
Аналогично toModifiedJulianDay, но вместо выбрасывания исключений возвращается NULL.
toMonday(date)
Округляет дату или дату-с-временем вниз до ближайшего понедельника. Возвращается дата.
toMonth(date)
Переводит дату или дату-с-временем в число типа UInt8, содержащее номер месяца (1-12).
toQuarter(date)
Переводит дату или дату-с-временем в число типа UInt8, содержащее номер квартала (1-4).
toRelativeDayNum(date, relates_on)
Переводит дату или дату-с-временем в номер дня, начиная с некоторого фиксированного момента в прошлом.
toRelativeHourNum(date, relates_on)
Переводит дату или дату-с-временем в номер часа, начиная с некоторого фиксированного момента в прошлом.
toRelativeMinuteNum(date, relates_on)
Переводит дату или дату-с-временем в номер минуты, начиная с некоторого фиксированного момента в прошлом.
toRelativeMonthNum(date, relates_on)
Переводит дату или дату-с-временем в номер месяца, начиная с некоторого фиксированного момента в прошлом.
toRelativeQuarterNum(date, relates_on)
Переводит дату или дату-с-временем в номер квартала, начиная с некоторого фиксированного момента в прошлом.
toRelativeSecondNum(date, relates_on)
Переводит дату или дату-с-временем в номер секунды, начиная с некоторого фиксированного момента в прошлом.
toRelativeWeekNum(date, relates_on)
Переводит дату или дату-с-временем в номер недели, начиная с некоторого фиксированного момента в прошлом.
toRelativeYearNum(date, relates_on)
Переводит дату или дату-с-временем в номер года, начиная с некоторого фиксированного момента в прошлом.
toSecond(date)
Переводит дату-с-временем в число типа UInt8, содержащее номер секунды в минуте (0-59). Секунды координации не учитываются.
toStartOfDay(date, [timezone])
Округляет дату-с-временем вниз до начала дня. Возвращается дата-с-временем.
toStartOfFifteenMinutes(date, [timezone])
Округляет дату-с-временем вниз до начала пятнадцатиминутного интервала.
toStartOfFiveMinutes(date, [timezone])
Округляет дату-с-временем вниз до начала пятиминутного интервала.
toStartOfHour(date, [timezone])
Округляет дату-с-временем вниз до начала часа.
toStartOfInterval(time_or_data, INTERVAL x unit [, time_zone])
Обобщение остальных функцийtoStartOf*. Например, toStartOfInterval(t, INTERVAL 1 year) возвращает то же самое, что и toStartOfYear(t), toStartOfInterval(t, INTERVAL 1 month) возвращает то же самое, что и toStartOfMonth(t), toStartOfInterval(t, INTERVAL 1 day) возвращает то же самое, что и toStartOfDay(t), toStartOfInterval(t, INTERVAL 15 minute) возвращает то же самое, что и toStartOfFifteenMinutes(t), и т.п.
toStartOfISOYear(date, [timezone])
Округляет дату или дату-с-временем вниз до первого дня ISO года. Возвращается дата. Начало ISO года отличается от начала обычного года, потому что в соответствии с ISO 8601:1988 первая неделя года - это неделя с четырьмя или более днями в этом году.
1 Января 2017 г. - воскресение, т.е. первая ISO неделя 2017 года началась в понедельник 2 января, поэтому 1 января 2017 это 2016 ISO-год, который начался 2016-01-04.
toStartOfMinute(date, [timezone])
Округляет дату-с-временем вниз до начала минуты.
toStartOfMonth(date, [timezone])
Округляет дату-с-временем вниз до начала месяца.
toStartOfQuarter(date, [timezone])
Округляет дату-с-временем вниз до начала квартала.
toStartOfSecond(date, [timezone])
Отсекает доли секунды.
Аргументы:
date — дата и время. DateTime64.
timezone — часовой пояс для возвращаемого значения (необязательно). Если параметр не задан, используется часовой пояс параметра value. String.
toStartOfTenMinutes(date, [timezone])
Округляет дату-с-временем вниз до начала десятиминутного интервала.
toStartOfWeek(t, [mode], [timezone]])
Округляет дату или дату-с-временем назад, до ближайшего воскресенья или понедельника, в соответствии с mode. Возвращается дата. Аргумент mode работает точно так же, как аргумент mode toWeek(). Если аргумент mode опущен, то используется режим 0.
toStartOfYear(date, [timezone])
Округляет дату или дату-с-временем вниз до первого дня года. Возвращается дата.
toTime(date)
Переводит дату-с-временем на некоторую фиксированную дату, сохраняя при этом время.
toTimezone(value, timezone)
Переводит дату или дату с временем в указанный часовой пояс. Часовой пояс - это атрибут типов Date и DateTime. Внутреннее значение (количество секунд) поля таблицы или результирующего столбца не изменяется, изменяется тип поля и, соответственно, его текстовое отображение.
Аргументы:
value — время или дата с временем. DateTime64.
timezone — часовой пояс для возвращаемого значения. String. Этот аргумент является константой, потому что toTimezone изменяет часовой пояс столбца (часовой пояс является атрибутом типов DateTime*).
toUnixTimestamp(date); toUnixTimestamp(str, [timezone])
Переводит строку, дату или дату-с-временем в Unix Timestamp, имеющий тип UInt32. Строка может сопровождаться вторым (необязательным) аргументом, указывающим часовой пояс.
toUTCTimestamp(time_val, time_zone)
Преобразует значение типа DateTime/DateTime64 из другого часового пояса в временную метку часового пояса UTC.
Аргументы:
time_val — Константное значение типа DateTime/DateTime64 или выражение. Типы DateTime/DateTime64
time_zone — Константное начение типа String или выражение, представляющее часовой пояс. String
toWeek(date, [mode], [timezone])
Переводит дату или дату-с-временем в число UInt8, содержащее номер недели. Второй аргументам mode задает режим, начинается ли неделя с воскресенья или с понедельника и должно ли возвращаемое значение находиться в диапазоне от 0 до 53 или от 1 до 53. Если аргумент mode опущен, то используется режим 0.
toISOWeek() эквивалентно toWeek(date,3).
Описание режимов (mode):
| Mode | Первый день недели | Диапазон | Неделя 1 это первая неделя … |
|---|---|---|---|
0 |
Воскресенье | 0-53 |
с воскресеньем в этом году |
1 |
Понедельник | 0-53 |
с 4-мя или более днями в этом году |
2 |
Воскресенье | 1-53 |
с воскресеньем в этом году |
3 |
Понедельник | 1-53 |
с 4-мя или более днями в этом году |
4 |
Воскресенье | 0-53 |
с 4-мя или более днями в этом году |
5 |
Понедельник | 0-53 |
с понедельником в этом году |
6 |
Воскресенье | 1-53 |
с 4-мя или более днями в этом году |
7 |
Понедельник | 1-53 |
с понедельником в этом году |
8 |
Воскресенье | 1-53 |
содержащая 1 января |
9 |
Понедельник | 1-53 |
содержащая 1 января |
Для режимов со значением «с 4 или более днями в этом году» недели нумеруются в соответствии с ISO 8601:1988:
- Если неделя, содержащая 1 января, имеет 4 или более дней в новом году, это неделя
1. - В противном случае это последняя неделя предыдущего года, а следующая неделя - неделя
1.
Для режимов со значением «содержит 1 января», неделя 1 – это неделя, содержащая 1 января. Не имеет значения, сколько дней нового года содержит эта неделя, даже если она содержит только один день. Так, если последняя неделя декабря содержит 1 января следующего года, то она считается неделей 1 следующего года.
toYear(date, [timezone])
Переводит дату или дату-с-временем в число типа UInt16, содержащее номер года (AD).
toYearWeek(date, [mode])
Возвращает год и неделю для даты. Год в результате может отличаться от года в аргументе даты для первой и последней недели года.
Аргумент mode работает так же, как аргумент mode toWeek(), значение mode по умолчанию - 0.
toISOYear() эквивалентно intDiv(toYearWeek(date,3),100).
Однако, есть отличие в работе функций toWeek() и toYearWeek(). toWeek() возвращает номер недели в контексте заданного года, и в случае, когда toWeek() вернёт 0, toYearWeek() вернёт значение, соответствующее последней неделе предыдущего года.
toYYYYMM(date)
Переводит дату или дату со временем в число типа UInt32, содержащее номер года и месяца (YYYY * 100 + MM).
toYYYYMMDD(date)
Переводит дату или дату со временем в число типа UInt32, содержащее номер года, месяца и дня (YYYY 10000 + MM 100 + DD).
toYYYYMMDDhhmmss(date)
Переводит дату или дату со временем в число типа UInt64 содержащее номер года, месяца, дня и время (YYYY 10000000000 + MM 100000000 + DD 1000000 + hh 10000 + mm * 100 + ss).
yesterday()
Возвращает вчерашнюю дату на момент выполнения запроса. Делает то же самое, что today() - 1. Функция не требует аргументов.
Функции для работы с массивами
array(x1, …), оператор [x1, …]
Создаёт массив из аргументов функции. Аргументы должны быть константами и иметь типы, для которых есть наименьший общий тип. Должен быть передан хотя бы один аргумент, так как иначе непонятно, какого типа создавать массив. То есть, с помощью этой функции невозможно создать пустой массив.
Возвращает результат типа Array(T), где T - наименьший общий тип от переданных аргументов.
arrayCompact(arr)
Удаляет последовательно повторяющиеся элементы из массива. Порядок результирующих значений определяется порядком в исходном массиве.
arrayCount([func,] arr1, …)
Возвращает количество элементов массива arr, для которых функция func возвращает не 0. Если func не указана - возвращает количество ненулевых элементов массива.
Функция arrayCount является функцией высшего порядка — в качестве первого аргумента ей можно передать лямбда-функцию.
arrayDistinct(arr)
Принимает массив, возвращает массив, содержащий только уникальные элементы исходного массива.
arrayElement(arr, n), оператор arr[n]
Достаёт элемент с индексом n из массива arr. n должен быть любым целочисленным типом. Индексы в массиве начинаются с единицы. Поддерживаются отрицательные индексы. В этом случае, будет выбран соответствующий по номеру элемент с конца. Например, arr[-1] - последний элемент массива.
Если индекс выходит за границы массива, то возвращается некоторое значение по умолчанию (0 для чисел, пустая строка для строк и т. п.), кроме случая с неконстантным массивом и константным индексом 0 (в этом случае будет ошибка Array indices are 1-based).
arrayFlatten(arr)
Преобразует массив массивов в плоский массив.
Функция:
- Оперирует с массивами любой вложенности.
- Не изменяет массив, если он уже плоский.
Результирующий массив содержит все элементы исходных массивов.
arraySort([func,] arr, …)
Возвращает массив arr, отсортированный в восходящем порядке. Если задана функция func, то порядок сортировки определяется результатом применения этой функции на элементы массива arr. Если func принимает несколько аргументов, то в функцию arraySort нужно передавать несколько массивов, которые будут соответствовать аргументам функции func.
Значения NULL, NaN и Inf сортируются по следующему принципу:
- Значения
-Infидут в начале массива. - Значения
NULLидут в конце массива. - Значения
NaNидут перед NULL. - Значения
Infидут перед NaN.
Функция arraySort является функцией высшего порядка — в качестве первого аргумента ей можно передать лямбда-функцию. В этом случае порядок сортировки определяется результатом применения лямбда-функции на элементы массива.
countEqual(arr, x)
Возвращает количество элементов массива arr, равное x.
empty([x])
Проверяет, является ли входной массив пустым.
Массив считается пустым, если он не содержит ни одного элемента.
Функция также поддерживает работу с типами String и UUID.
Возвращает 1 для пустого массива или 0 — для непустого массива.
groupArrayArray(array_of_arrays)
Возвращает объединение массивов из array_of_arrays.
has(arr, elem)
Проверяет наличие элемента elem в массиве arr. Возвращает 0, если элемента в массиве нет, или 1, если есть.
NULL обрабатывается как значение.
hasAll(set, subset)
Проверяет, является ли один массив подмножеством другого.
Аргументы:
set – массив любого типа с набором элементов.
subset – массив любого типа со значениями, которые проверяются на вхождение в set.
Возвращает 1, если set содержит все элементы из subset, в противном случае - 0.
Пустой массив является подмножеством любого массива.
NULL обрабатывается как значение.
Порядок значений в обоих массивах не имеет значения.
hasAny(array1, array2)
Проверяет, имеют ли два массива хотя бы один общий элемент.
Аргументы:
array1 – массив любого типа с набором элементов.
array2 – массив любого типа с набором элементов.
NULL обрабатывается как значение.
Порядок значений в обоих массивах не имеет значения.
hasSubstr(array1, array2)
Проверяет, все ли элементы array2 отображаются в array1 в одном и том же порядке. Следовательно, функция вернет значение 1 тогда и только тогда, когда array1 = префикс + array2 + суффикс.
Другими словами, функция будут проверять, все ли элементы array2 содержатся в array1, как функция hasAll. Кроме того, она проверяет, что элементы находятся в одинаковом порядке как в array1, так и в array2.
Аргументы:
array1 – массив любого типа с набором элементов.
array2 – массив любого типа с набором элементов.
Вызывает исключение NO_COMMON_TYPE, если элементы array1 и array2 не имеют общего супертипа.
Специфические свойства
Функция вернет 1, если array2 пуст.
Null обрабатывается как значение. Другими словами, hasSubstr([1, 2, NULL, 3, 4], [2,3]) вернет 0. Однако hasSubstr([1, 2, NULL, 3, 4], [2,NULL,3]) вернет 1.
Порядок значений в обоих массивах имеет значение.
indexOf(arr, x)
Возвращает индекс первого элемента x (начиная с 1), если он есть в массиве, или 0, если его нет.
Элементы, равные NULL, обрабатываются как обычные значения.
length(arr)
Возвращает количество элементов в массиве. Тип результата - UInt64. Функция также работает для строк.
notEmpty(arr)
Проверяет, является ли входной массив непустым.
Массив считается непустым, если он содержит хотя бы один элемент.
Функция также поддерживает работу с типами String и UUID.
range(end), range([start, ] end [, step])
Возвращает массив чисел от start до end - 1 с шагом step.
Аргументы:
start — начало диапазона. Обязательно, когда указан step. По умолчанию равно 0. UInt.
end — конец диапазона. Обязательный аргумент. Должен быть больше, чем start. UInt.
step — шаг обхода. Необязательный аргумент. По умолчанию равен 1. UInt.
Особенности реализации:
Не поддерживаются отрицательные значения аргументов: start, end, step имеют тип UInt.
Если в результате запроса создаются массивы суммарной длиной больше, чем количество элементов, указанное настройкой function_range_max_elements_in_block, то генерируется исключение.
Возвращает Null если любой аргумент Nullable(Nothing) типа. Генерируется исключение если любой аргумент Null (Nullable(T) тип).
reverse(arr)
Возвращает массив того же размера, что и исходный массив arr, содержащий элементы в обратном порядке.
Функции для работы со строками
appendTrailingCharIfAbsent(s, c)
Если строка s непустая и не содержит символ c на конце, то добавляет символ c в конец.
concat(s1, s2, ...)
Склеивает строки, переданные в аргументы, в одну строку без разделителей.
Возвращает строку, полученную в результате склейки аргументов.
Если любой из аргументов имеет значение NULL, concat возвращает значение NULL.
concatAssumeInjective(s1, s2, ...)
Аналогична concat. Разница заключается в том, что вам нужно убедиться, что concat(s1, s2, ...) → sn является инъективным, так как это предположение будет использоваться для оптимизации GROUP BY.
Функция называется «инъективной», если она возвращает разные значения для разных аргументов. Или, иными словами, функция никогда не выдаёт одно и то же значение, если аргументы разные.
concatWithSeparator(sep, s1, s2, ...)
Склеивает строки, переданные в аргументы, в одну строку с разделителем sep.
Возвращает строку, полученную в результате склейки аргументов.
Если любой из аргументов имеет значение NULL, concatWithSeparator возвращает значение NULL.
concatWithSeparatorAssumeInjective(sep, s1, s2, ...)
Аналогична concatWithSeparator. Разница заключается в том, что вам нужно убедиться, что concatWithSeparator(s1, s2, ...) → sn является инъективным, так как это предположение будет использоваться для оптимизации GROUP BY.
Функция называется «инъективной», если она возвращает разные значения для разных аргументов. Или, иными словами, функция никогда не выдаёт одно и то же значение, если аргументы разные.
empty(s)
Проверяет, является ли входная строка пустой.
Строка считается непустой, если содержит хотя бы один байт, пусть даже это пробел или нулевой байт.
Функция также поддерживает работу с типами Array и UUID.
Возвращает 1 для пустой строки и 0 — для непустой строки.
endsWith(s, suffix)
Возвращает 1, если строка s завершается указанным в suffix суффиксом, и 0 в противном случае.
endsWithUTF8(s, suffix)
Возвращает 1, если строка s завершается указанным в suffix суффиксом, и 0 в противном случае. Различие между endsWith и endsWithUTF8 в том, что endsWithUTF8 воспринимает кодировку UTF-8. Например, endsWithUTF8('中国', '\xbd') вернёт 1, в то время как endsWith(s, suffix) вернёт 0.
isValidUTF8(s)
Возвращает 1, если набор байтов является корректным в кодировке UTF-8, иначе - 0.
leftPad(string, length, [pad_string])
Дополняет текущую строку слева пробелами или указанной строкой (несколько раз, если необходимо), пока результирующая строка не достигнет заданной длины.
Аргументы:
string — входная строка, которую необходимо дополнить. String.
length — длина результирующей строки. UInt. Если указанное значение меньше, чем длина входной строки, то входная строка возвращается как есть.
pad_string — строка, используемая для дополнения входной строки. String. Необязательный параметр. Если не указано, то входная строка дополняется пробелами.
leftPadUTF8(string, length, [pad_string])
Дополняет текущую строку слева пробелами или указанной строкой (несколько раз, если необходимо), пока результирующая строка не достигнет заданной длины. В отличие от функции leftPad, измеряет длину строки не в байтах, а в кодовых точках Unicode.
Аргументы:
string — входная строка, которую необходимо дополнить. String.
length — длина результирующей строки. UInt. Если указанное значение меньше, чем длина входной строки, то входная строка возвращается как есть.
pad_string — строка, используемая для дополнения входной строки. String. Необязательный параметр. Если не указано, то входная строка дополняется пробелами.
length(s)
Возвращает количество элементов в строке. Тип результата - UInt64. Функция также работает для массивов.
lengthUTF8(s)
Возвращает длину строки в кодовых точках Unicode (не символах), при допущении, что строка содержит набор байтов, являющийся текстом в кодировке UTF-8. Если допущение не выполнено, то результат не определён. Тип результата — UInt64.
lower(s)
Переводит ASCII-символы латиницы в строке в нижний регистр.
lowerUTF8(s)
Переводит строку в нижний регистр, при допущении, что строка содержит набор байтов, представляющий текст в кодировке UTF-8. Не учитывает язык. То есть, для турецкого языка, результат может быть не совсем верным. Если длина UTF-8 последовательности байтов различна для верхнего и нижнего регистра кодовой точки, то для этой кодовой точки результат работы может быть некорректным. Если строка содержит набор байтов, не являющийся UTF-8, то поведение не определено.
notEmpty(s)
Проверяет, является ли входная строка s непустой.
Строка считается непустой, если содержит хотя бы один байт, пусть даже это пробел или нулевой байт.
Функция также поддерживает работу с типами Array и UUID.
repeat(s, n)
Повторяет строку определенное количество раз и объединяет повторяемые значения в одну строку. Если n < 1, то функция вернет пустую строку.
Аргументы:
s — строка для повторения. String.
n — количество повторов. UInt.
reverse(s)
Разворачивает строку s (как последовательность байтов).
reverseUTF8(s)
Разворачивает последовательность кодовых точек Unicode, при допущении, что строка s содержит набор байтов, представляющий текст в кодировке UTF-8. Иначе — поведение не определено (не выбрасывает исключение).
rightPad(string, length, [pad_string])
Дополняет текущую строку справа пробелами или указанной строкой (несколько раз, если необходимо), пока результирующая строка не достигнет заданной длины.
Аргументы:
string — входная строка, которую необходимо дополнить. String.
length — длина результирующей строки. UInt. Если указанное значение меньше, чем длина входной строки, то входная строка возвращается как есть.
pad_string — строка, используемая для дополнения входной строки. String. Необязательный параметр. Если не указано, то входная строка дополняется пробелами.
rightPadUTF8(string, length, [pad_string])
Дополняет текущую строку слева пробелами или указанной строкой (несколько раз, если необходимо), пока результирующая строка не достигнет заданной длины. В отличие от функции rightPad, измеряет длину строки не в байтах, а в кодовых точках Unicode.
space(n)
Повторяет символ пробела n раз. Если n < 1, возвращает пустую строку.
startsWith(s, prefix)
Возвращает 1, если строка начинается указанным префиксом, в противном случае 0.
startsWithUTF8(s, prefix)
Возвращает 1, если строка начинается указанным префиксом, в противном случае 0. Разница между startsWithUTF8 и startsWith заключается в том, что startsWithUTF8 проверяет соответствие str и prefix с помощью символов UTF-8.
substring(s, offset, length)
Возвращает подстроку, начиная с байта по индексу offset, длины length байт. Индексация символов — начиная с 1 (как в стандартном SQL). Аргументы offset и length должны быть константами.
substringUTF8(s, offset, length)
Так же, как substring, но для кодовых точек Unicode. Работает при допущении, что строка содержит набор байтов, представляющий текст в кодировке UTF-8. Если допущение не выполнено, то возвращает неопределённый результат (не выбрасывает исключение).
substringIndex(s, delim, count)
Возвращает подстроку s перед подсчетом вхождений разделителя delim, как в Spark или MySQL.
substringIndexUTF8(s, delim, count)
Возвращает подстроку s перед количеством вхождений разделителя delim, специально для кодовых точек Unicode.
Предполагается, что строка содержит допустимый текст в кодировке UTF-8. Если это предположение нарушено, исключение не генерируется, и результат не определен.
toValidUTF8(s)
Заменяет некорректные символы UTF-8 на символ � (U+FFFD). Все идущие подряд некорректные символы схлопываются в один заменяющий символ.
trim([[LEADING|TRAILING|BOTH] trim_character FROM] s)
Удаляет все указанные символы с начала или окончания строки. По умолчанию удаляет все последовательные вхождения обычных пробелов (32 символ ASCII) с обоих концов строки.
Аргументы:
trim_character — один или несколько символов, подлежащие удалению. String.
input_string — строка для обрезки. String.
trimBoth(s)
Удаляет все последовательные вхождения обычных пробелов (32 символ ASCII) с обоих концов строки. Не удаляет другие виды пробелов (табуляция, пробел без разрыва и т. д.).
trimLeft(s)
Удаляет все последовательные вхождения обычных пробелов (32 символ ASCII) с левого конца строки. Не удаляет другие виды пробелов (табуляция, пробел без разрыва и т. д.).
trimRight(s)
Удаляет все последовательные вхождения обычных пробелов (32 символ ASCII) с правого конца строки. Не удаляет другие виды пробелов (табуляция, пробел без разрыва и т. д.).
upper(s)
Переводит ASCII-символы латиницы в строке в верхний регистр.
upperUTF8(s)
Переводит строку в верхний регистр, при допущении, что строка содержит набор байтов, представляющий текст в кодировке UTF-8. Не учитывает язык. То есть, для турецкого языка, результат может быть не совсем верным. Если длина UTF-8 последовательности байтов различна для верхнего и нижнего регистра кодовой точки, то для этой кодовой точки, результат работы может быть некорректным. Если строка содержит набор байтов, не являющийся UTF-8, то поведение не определено.
Функции поиска в строках
countMatches(haystack, pattern)
Возвращает количество совпадений, найденных в строке haystack, для регулярного выражения pattern.
countSubstrings(haystack, needle[, start_pos])
Возвращает количество вхождений подстроки needle в строку haystack, начиная с опционально задаваемой позиции start_pos (по умолчанию - 0).
extract(haystack, pattern)
Извлечение фрагмента строки по регулярному выражению. Если haystack не соответствует регулярному выражению pattern, то возвращается пустая строка. Если регулярное выражение не содержит subpattern-ов, то вынимается фрагмент, который подпадает под всё регулярное выражение. Иначе вынимается фрагмент, который подпадает под первый subpattern.
extractAll(haystack, pattern)
Извлечение всех фрагментов строки по регулярному выражению. Если haystack не соответствует регулярному выражению pattern, то возвращается пустая строка. Возвращается массив строк, состоящий из всех соответствий регулярному выражению. В остальном, поведение аналогично функции extract (по прежнему, вынимается первый subpattern, или всё выражение, если subpattern-а нет).
extractAllGroupsHorizontal(haystack, pattern)
Разбирает строку haystack на фрагменты, соответствующие группам регулярного выражения pattern. Возвращает массив массивов, где первый массив содержит все фрагменты, соответствующие первой группе регулярного выражения, второй массив - соответствующие второй группе, и т.д.
Функция extractAllGroupsHorizontal работает медленнее, чем функция extractAllGroupsVertical.
extractAllGroupsVertical(haystack, pattern)
Разбирает строку haystack на фрагменты, соответствующие группам регулярного выражения pattern. Возвращает массив массивов, где каждый массив содержит по одному фрагменту, соответствующему каждой группе регулярного выражения. Фрагменты группируются в массивы в соответствии с порядком появления в исходной строке.
hasSubsequence(haystack, needle)
Возвращает 1 если needle является подпоследовательностью haystack, иначе 0.
Аргументы:
haystack — строка, по которой выполняется поиск.
needle — подпоследовательность, которую необходимо найти.
hasSubsequenceCaseInsensitive(haystack, needle)
Работает аналогично hasSubsequence, но без учёта регистра.
hasSubsequenceUTF8(haystack, needle)
Работает аналогично hasSubsequence, но воспринимает символы в кодировке UTF-8.
hasSubsequenceCaseInsensitiveUTF8(haystack, needle)
Работает аналогично hasSubsequenceUTF8, но без учёта регистра.
ilike(haystack, pattern)
Нечувствительный к регистру вариант функции like.
Аргументы:
haystack — входная строка.
pattern — если pattern не содержит процента или нижнего подчеркивания, тогда pattern представляет саму строку. Нижнее подчеркивание (_) в pattern обозначает любой отдельный символ. Знак процента (%) соответствует последовательности из любого количества символов: от нуля и более.
Возвращаемые значения:
1, если строка соответствует pattern.
0, если строка не соответствует pattern.
like(haystack, pattern)
Проверка строки на соответствие простому регулярному выражению. Регулярное выражение может содержать метасимволы % и _.
% обозначает любое количество любых байт (в том числе, нулевое количество символов).
_ обозначает один любой байт.
Для экранирования метасимволов, используется символ \ (обратный слеш). Смотрите замечание об экранировании в описании функции match.
Для регулярных выражений вида %needle% действует более оптимальный код, который работает также быстро, как функция position. Для остальных регулярных выражений, код аналогичен функции match.
multiFuzzyMatchAllIndices(haystack, distance, [pattern1, pattern2, …, patternn])
То же, что и multiFuzzyMatchAny, только возвращает массив всех индексов всех подходящих регулярных выражений в любом порядке в пределах константного редакционного расстояния.
multiFuzzyMatch* функции не поддерживают UTF-8 закодированные регулярные выражения, и такие выражения рассматриваются как байтовые из-за ограничения hyperscan.
multiFuzzyMatchAny(haystack, distance, [pattern1, pattern2, …, patternx])
То же, что и multiMatchAny, но возвращает 1 если любой шаблон соответствует haystack в пределах константного редакционного расстояния. Эта функция основана на экспериментальной библиотеке hyperscan и может быть медленной для некоторых частных случаев. Производительность зависит от значения редакционного расстояния и используемых шаблонов, но всегда медленнее по сравнению с non-fuzzy вариантами.
multiFuzzyMatchAnyIndex(haystack, distance, [pattern1, pattern2, …, patternx])
То же, что и multiFuzzyMatchAny, только возвращает любой индекс подходящего регулярного выражения в пределах константного редакционного расстояния.
multiMatchAllIndices(haystack, [pattern1, pattern2, …, patternx])
То же, что и multiMatchAny, только возвращает массив всех индексов всех подходящих регулярных выражений в любом порядке.
multiMatchAny(haystack, [pattern1, pattern2, …, patternx])
То же, что и match, но возвращает 0, если ни одно регулярное выражение не подошло и 1, если хотя бы одно. Используется библиотека hyperscan для соответствия регулярных выражений. Для шаблонов на поиск многих подстрок в строке, лучше используйте multiSearchAny, так как она работает существенно быстрее.
Длина любой строки из haystack должна быть меньше 2^32 байт, иначе выбрасывается исключение. Это ограничение связано с ограничением hyperscan API.
multiMatchAnyIndex(haystack, [pattern1, pattern2, …, patternx])
То же, что и multiMatchAny, только возвращает любой индекс подходящего регулярного выражения.
multiSearchAllPositions(haystack, [needle1, needle2, ..., needlen])
Аналогично position, но возвращает массив позиций (в байтах) найденных соответствующих подстрок в строке. Позиции индексируются, начиная с 1.
Поиск выполняется по последовательностям байтов без учета кодировки строки и сортировки.
Для поиска в ASCII без учета регистра используйте функцию multiSearchAllPositionsCaseInsensitive.
Для поиска в UTF-8 используйте функцию multiSearchAllPositionsUTF8.
Для поиска без учета регистра в UTF-8 используйте функцию multiSearchAllPositionsCaseInsensitiveUTF8.
Аргументы:
haystack — строка, в подстроке которой будет производиться поиск.
needle — подстрока для поиска.
multiSearchAllPositionsUTF8(haystack, [needle1, needle2, ..., needlen])
См. multiSearchAllPositions.
multiSearchAny(haystack, [needle1, needle2, …, needlen])
Возвращает 1, если хотя бы одна подстрока needle нашлась в строке haystack и 0 иначе.
Для поиска без учета регистра и/или в кодировке UTF-8 используйте функции multiSearchAnyCaseInsensitive, multiSearchAnyUTF8, multiSearchAnyCaseInsensitiveUTF8.
Во всех функциях multiSearch* количество needles должно быть меньше 2^8 из-за особенностей реализации.
multiSearchFirstIndex(haystack, [needle1, needle2, …, needlen])
Возвращает индекс i (нумерация с 1) первой найденной строки needle в строке haystack и 0 иначе.
Для поиска без учета регистра и/или в кодировке UTF-8 используйте функции multiSearchFirstIndexCaseInsensitive, multiSearchFirstIndexUTF8, multiSearchFirstIndexCaseInsensitiveUTF8.
multiSearchFirstPosition(haystack, [needle1, needle2, …, needlen])
Работает так же, как и position, только возвращает позицию первого вхождения любого из needles.
Для поиска без учета регистра и/или в кодировке UTF-8 используйте функции multiSearchFirstPositionCaseInsensitive, multiSearchFirstPositionUTF8, multiSearchFirstPositionCaseInsensitiveUTF8.
ngramDistance(haystack, needle)
Вычисление 4-граммного расстояния между haystack и needle: считается симметрическая разность между двумя мультимножествами 4-грамм и нормализуется на сумму их мощностей. Возвращает число float от 0 до 1 – чем ближе к нулю, тем больше строки похожи друг на друга. Если константный needle или haystack больше чем 32КБ, выбрасывается исключение. Если некоторые строки из неконстантного haystack или needle больше 32КБ, расстояние всегда равно 1.
ngramSearch(haystack, needle)
То же, что и ngramDistance, но вычисляет несимметричную разность между needle и haystack – количество n-грамм из needle минус количество общих n-грамм, нормированное на количество n-грамм из needle. Чем ближе результат к 1, тем вероятнее, что needle внутри haystack. Может быть использовано для приближенного поиска.
notILike(haystack, pattern)
То же, что ilike, но с отрицанием.
notLike(haystack, pattern)
То же, что like, но с отрицанием.
position(haystack, needle)
Поиск подстроки needle в строке haystack.
Возвращает позицию (в байтах) найденной подстроки в строке, начиная с 1, или 0, если подстрока не найдена.
Для поиска без учета регистра используйте функцию positionCaseInsensitive.
Аргументы:
haystack — строка, по которой выполняется поиск.
needle — подстрока, которую необходимо найти.
start_pos — опциональный параметр, позиция символа в строке, с которого начинается поиск. UInt.
positionCaseInsensitive(haystack, needle[, start_pos])
Такая же, как и position, но работает без учета регистра. Возвращает позицию в байтах найденной подстроки в строке, начиная с 1, или 0, если подстрока не найдена.
Работает при допущении, что строка содержит набор байт, представляющий текст в однобайтовой кодировке. Если допущение не выполнено — то возвращает неопределенный результат (не выбрасывает исключение). Если символ может быть представлен с помощью двух байтов, он будет представлен двумя байтами и так далее.
positionCaseInsensitiveUTF8(haystack, needle[, start_pos])
Такая же, как и positionUTF8, но работает без учета регистра. Возвращает позицию (в кодовых точках Unicode) найденной подстроки в строке, начиная с 1, или 0, если подстрока не найдена.
Работает при допущении, что строка содержит набор кодовых точек, представляющий текст в кодировке UTF-8. Если допущение не выполнено — то возвращает неопределенный результат (не выбрасывает исключение). Если символ может быть представлен с помощью двух кодовых точек, он будет представлен двумя и так далее.
regexpExtract(haystack, pattern[, index])
Извлекает первую строку в haystack, которая соответствует шаблону pattern регулярного выражения и соответствует индексу index группы регулярных выражений.
Аргументы:
haystack — строка, в которой должен быть подобран шаблон регулярного выражения.
pattern — строка, регулярное выражение, должна быть постоянной.
index – целое число, большее или равное 0 при значении по умолчанию 1. Он указывает, какую группу регулярных выражений извлекать. UInt или Int. Необязательно.
pattern может содержать несколько групп регулярных выражений, index указывает, какую группу регулярных выражений извлекать. index, равный index, означает соответствие всему регулярному выражению.
Функции разбиения и слияния строк и массивов
alphaTokens(s, [max_substrings])
Разделяет строку s на буквенные подстроки заданное в max_substrings количество раз. Если max_substrings не задано, функция вернёт столько подстрок, сколько существует в строке.
Пример:
alphaTokens('abca1abc')
Результат выполнения:
['abca', 'abc']
arrayStringConcat(arr[, separator])
Склеивает строковые представления элементов массива с разделителем separator. separator - необязательный параметр, константная строка, по умолчанию равен пустой строке. Возвращается строка.
extractAllGroups(text, regexp)
Извлекает все группы из непересекающихся подстрок, сопоставляемых регулярным выражением.
Аргументы:
text - строка для поиска.
regexp - регулярное выражение.
ngrams(string, ngramsize)
Выделяет из UTF-8 строки отрезки (n-граммы) размером ngramsize символов. Возвращает массив n-грамм.
Аргументы:
string — строка. String or FixedString.
ngramsize — размер n-грамм. UInt.
splitByChar(separator, s)
Разбивает строку на подстроки, используя в качестве разделителя separator. separator должен быть константной строкой из ровно одного символа. Возвращается массив выделенных подстрок. Могут выделяться пустые подстроки, если разделитель идёт в начале или в конце строки, или если идёт более одного разделителя подряд.
Аргументы:
separator — разделитель, состоящий из одного символа. String.
s — разбиваемая строка. String.
Пустая подстрока, может быть возвращена, когда:
- Разделитель находится в начале или конце строки.
- Задано несколько последовательных разделителей.
- Исходная строка
sпуста.
splitByNonAlpha(s)
Разбивает строку s на подстроки, используя в качестве разделителей пробельные символы и символы пунктуации. Возвращает массив подстрок.
splitByRegexp(regexp, s)
Разбивает строку на подстроки, разделенные регулярным выражением. В качестве разделителя используется строка регулярного выражения regexp. Если regexp пустая, функция разделит строку s на массив одиночных символов. Если для регулярного выражения совпадения не найдено, строка s не будет разбита.
Аргументы:
regexp — регулярное выражение. Константа. String или FixedString.
s — разбиваемая строка. String.
Пустая подстрока может быть возвращена, если:
- Непустое совпадение с регулярным выражением происходит в начале или конце строки.
- Имеется несколько последовательных совпадений c непустым регулярным выражением.
- Исходная строка
sпуста, а регулярное выражение не пустое.
splitByString(separator, s)
Разбивает строку на подстроки, разделенные строкой. В качестве разделителя использует константную строку separator, которая может состоять из нескольких символов. Если строка separator пуста, то функция разделит строку s на массив из символов.
Аргументы:
separator — разделитель. String.
s — разбиваемая строка. String.
Пустая подстрока, может быть возвращена, когда:
- Разделитель находится в начале или конце строки.
- Задано несколько последовательных разделителей.
- Исходная строка s пуста.
splitByWhitespace(s)
Разбивает строку на подстроки, используя в качестве разделителей пробельные символы. Возвращает массив подстрок.
Функции поиска и замены в строках
regexpQuoteMeta(s)
Добавляет обратную косую черту перед этими символами, имеющими особое значение в регулярных выражениях: \0, \\, |, (, ), ^, $, ., [, ], ?, *, +, {, :, -.
Эта реализация немного отличается от re2::RE2::QuoteMeta. Она экранирует нулевой байт как \0 вместо \x00 и экранирует только необходимые символы.
replaceAll(haystack, pattern, replacement)
Замена всех вхождений подстроки pattern в haystack на подстроку replacement. Здесь и далее, pattern и replacement должны быть константами.
replaceOne(haystack, pattern, replacement)
Замена первого вхождения, если такое есть, подстроки pattern в haystack на подстроку replacement.
replaceRegexpOne(haystack, pattern, replacement)
Замена по регулярному выражению pattern. Регулярное выражение re2. Заменяется только первое вхождение, если есть. В качестве replacement может быть указан шаблон для замен. Этот шаблон может включать в себя подстановки \0-\9. Подстановка \0 - вхождение регулярного выражения целиком. Подстановки \1-\9 - соответствующие по номеру subpattern-ы. Для указания символа \ в шаблоне, он должен быть экранирован с помощью символа \. Также помните о том, что строковый литерал требует ещё одно экранирование.
replaceRegexpAll(haystack, pattern, replacement)
То же что и replaceRegexpOne, но делается замена всех вхождений.
tokens(s)
Разбивает строку на токены, используя в качестве разделителей не буквенно-цифровые символы ASCII. Возвращает массив токенов.
Аргументы:
s — набор байтов. String.
Статистические функции
approxdistinct(table)
Возвращает приблизительное значение уникальных записей в таблице, не являющихся NULL.
Табличные функции
format(format_name, [structure], data)
Анализирует данные из аргументов в соответствии с указанным в format_name форматом ввода. Если аргумент structure не указан, он извлекается из данных.
Возвращает таблицу с данными, проанализированными из аргумента data в соответствии с указанным форматом и указанной или извлеченной структурой.
Функции для работы с UUID
notEmpty(UUID)
Проверяет, является ли входной UUID непустым. Возвращает 1, если UUID не пустой, 0 - в противном случае.
UUID считается пустым, если он содержит все нули (нулевой UUID).
Функция также поддерживает работу с типами Array и String.
Прочие функции
greatest(a, b)
Возвращает наибольшее значение из a и b.
least(a, b)
Возвращает наименьшее значение из a и b.